

LIMA is CEA-List’s multilingual language analyzer for business and other intelligence reporting, electronic document management (EDM), content summarization, and monitoring of content streams like social media. It’s among the best tools in the world for processing French, Arabic, and English, and it supports more than 60 languages in total.
LIMA is a multilingual language analyzer. It runs morphological, syntactic, semantic, and lexical analyses on text-based content. It’s well-suited to use cases that require processing large quantity of unstructured texts, and it excels in tasks like classifying texts, automatically extracting parts of documents, summarizing documents, and even analyzing content streams, such as social media posts. In its most recent version, DeepLIMA, also known as LIMA v3.0, demonstrates state-of-the-art mastery of more than 60 languages.
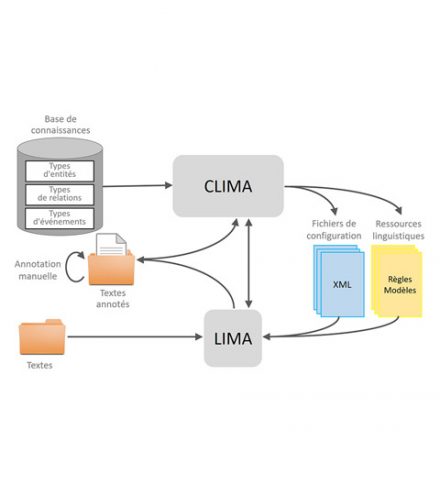
The engine comes with a configurator, CLIMA, which allows users to adapt it to new domains. CLIMA helps users define knowledge structures and provide useful examples for adaptation.
LIMA is Free Software, available under the MIT license. CEA-List is at your disposal to help you develop specific features or resources or if you need a commercial licence for any reason.

Main advantages:
The ANT’box EDM solution is built on LIMA technology


Divora is a tool developed by CEA-List for automatically structuring orally dictated reports. It lets users write reports directly in the field using a mobile device with a voice interface.
A first speech recognition module converts speech into text. The text is then processed by a second module, built on CEA-List’s LIMA multilingual analyzer, where terms significant to the automated generation of the report and the semantic relationships between these terms are identified.
Divora was developed as part of a FactoryLab project for a particular use case: construction site inspection and management.
In the news: Divora automates report writing at work
A Neural Approach For Inducing Multilingual Resources And Natural Language Processing Tools For Low-Resource Languages, O. Zennaki, N. Semmar, and L. Besacier. Natural Language Engineering, vol. 25, no. 1, p. 43-67, 2019.
Using pseudo-senses for improving the extraction of synonyms from word embeddings, O. Ferret. 56th Annual Meeting of the Association for Computational Linguistics (ACL 2018), short paper session. Melbourne, Australia: Association for Computational Linguistics, 2018, pp. 351-357.
Exploiting a More Global Context for Event Detection Through Bootstrapping, D. Kodelja, R. Besançon, and O. Ferret. 41st European Conference on Information Retrieval (ECIR 2019): Advances in Information Retrieval, short article session. Cologne, Germany: Springer International Publishing, 2019, pp. 763-770.
Joint Learning of Pre-Trained and Random Units for Domain Adaptation in Part-of-Speech Tagging, S. Meftah, Y. Tamaazousti, N. Semmar, H. Essafi, and F. Sadat. 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL HLT 2019), short paper session. Minneapolis, Minnesota: Association for Computational Linguistics, Jun. 2019, pp. 4107-4112.
Multimodal Entity Linking for Tweets, O. Adjali, R. Besançon, O. Ferret, H. L. Borgne, and B. Grau. 42st European Conference on Information Retrieval (ECIR 2020): Advances in Information Retrieval, Lisbon, Portugal, 2020.

