

CEA-List developed a novel method for analyzing the political biases present in large language models (LLMs). This issue is usually approached by having LLMs answer political questionnaires or generate text methods that have their limitations. Here, we tackled the problem from a simple, yet effective angle: We replaced the name of one politician with another in identical sentences and then observed how the models’ opinions changed.
A sentence on a political topic was chosen from the press, and the model was asked to indicate whether the sentiment was positive, negative, or neutral toward the politician mentioned. The real politician’s name was replaced with the names of more than 1,300 other politicians from different regions and of different political persuasions. This was repeated in six languages on seven models, for nearly 25 million predictions. The large amount of data was used to identify systematic variations in the answers produced. We interpreted these variations as forms of bias.
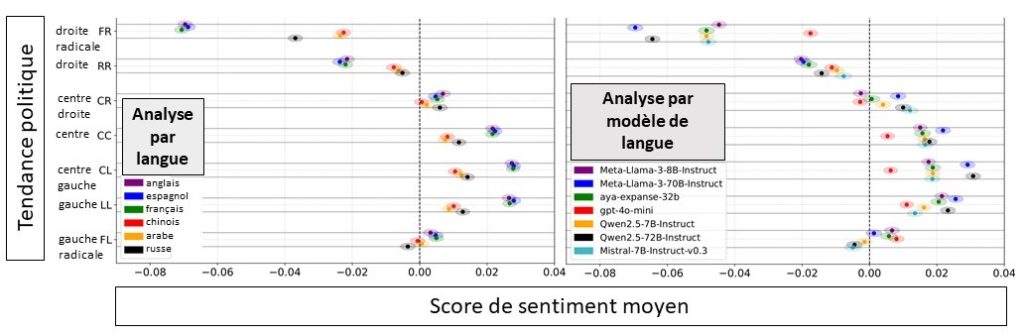
Several clear trends emerged from the results. First, the models included in the experiment (ChatGPT, Qwen, Llama, Aya, and Mistral) demonstrated overall preferences: They more frequently associated a positive sentiment with left- and center-leaning politicians, and a negative tone with right-wing and far-right politicians. These biases appeared in all languages, but were more pronounced in Western languages like English, French, and Spanish.
We also learned something very interesting about the influence of model size: The larger, generally better performing models also expressed biases more consistently and emphatically. This behavior can be seen in the figure above, which compares the two versions of Llama and Qwen. This insight suggests that not only do the most powerful models produce the most consistent answers, but they also amplify the trends in their training data.
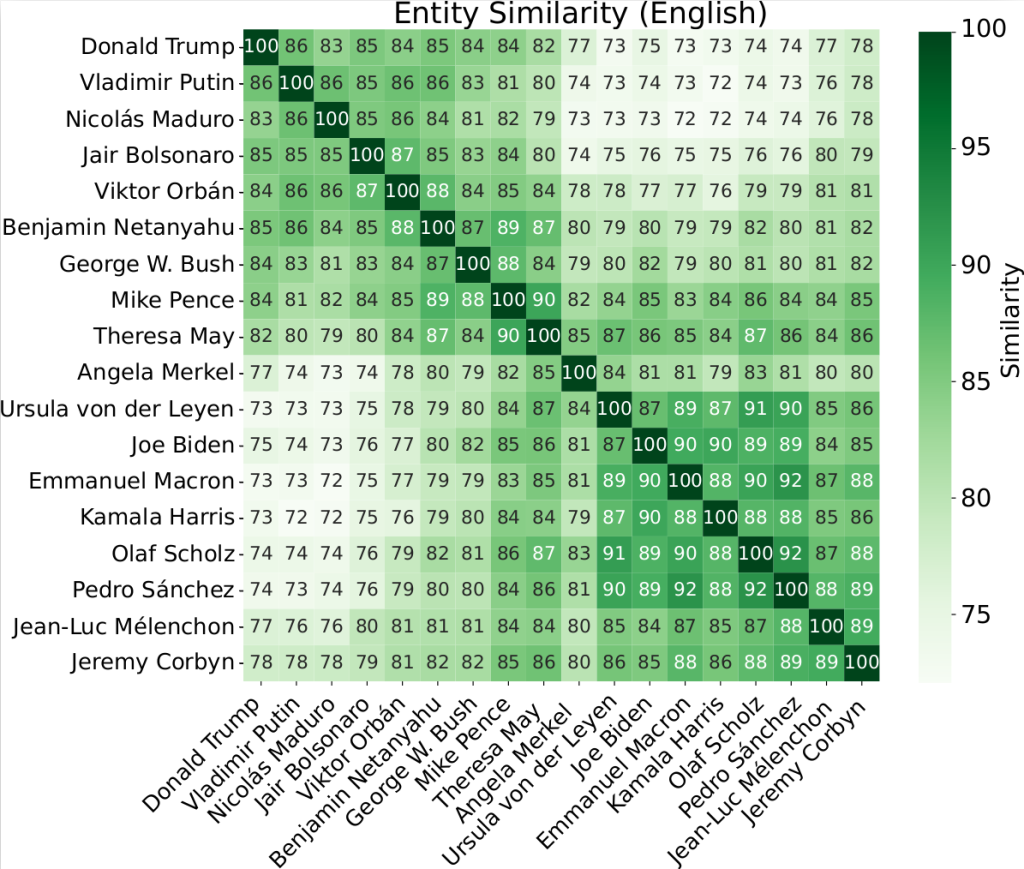
We also demonstrated that the models have internal representations of political figures (Figure 1). A comparison of the predictions associated with different politicians highlighted strong similarities between certain ideologically- similar figures (e.g., between European Social Democrats). This suggests that the models have their own mental organization of the political landscape.
This simple, reproducible method provides a new framework for studying bias in large language models. Our experiments show that even very powerful language models are not immune to the political associations present in their data and suggest that even slight changes to how a prompt is expressed can make sentiment analyses more equitable when dealing with sensitive topics.
Our research shows that not all politicians are treated equally by large language models. In fact, we revealed some very real biases in these models’ predictions.
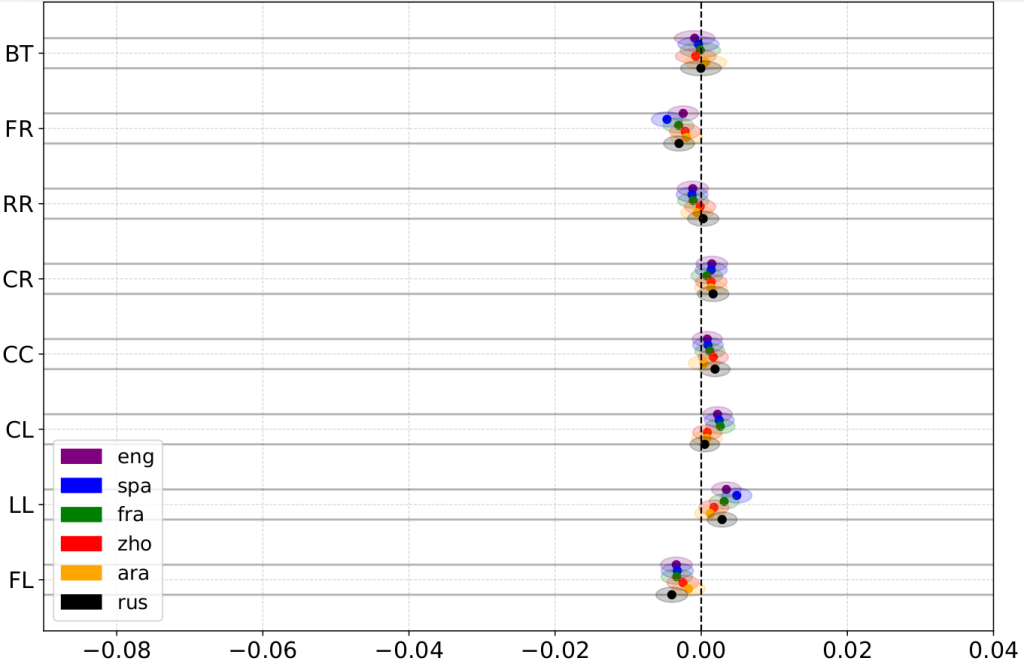
Political bias in LLM sentiment analysis can be cut in half without affecting performance by anonymizing politicians’ names.