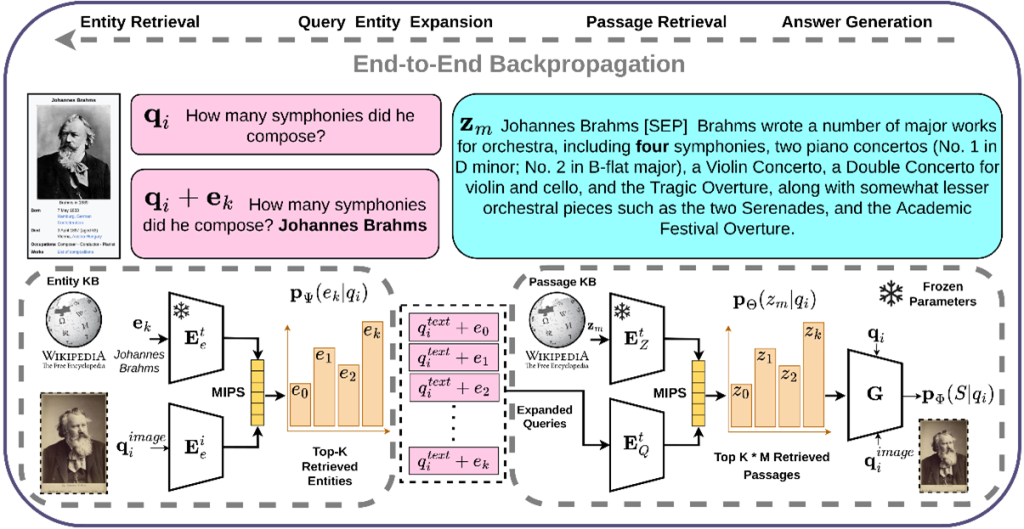
Knowledge-based Visual Question Answering about named Entities (KVQAE) has recently garnered attention as a benchmark task for assessing the ability of information retrieval systems to understand visual and textual information in depth. In the standard visual question answering (VQA) task, questions can be answered using images alone. KQVAE, however, requires answers to be retrieved from an external knowledge base made up of both text and images. In a KQVAE system (see figure on the right) the input consists of a question in text form (e.g., “How many symphonies did he compose?”) and an image (e.g., a photo of Johannes Brahms). A set of documents combining text and images (Wikipedia pages) must be searched to find the answer.
CEA-List used its RAG-based MiRAG model to complete this KVQAE task, combining an information retrieval model and an answer generation model. The figure above illustrates the main steps in this approach. The basic idea is to search at different levels of granularity (entity and passage) from a multimodal question with textual and visual inputs. Extracting information at different levels gradually refines the question. The answers are then generated using the generation model.
The search is first carried out at the entity (document) level to identify a set of candidate entities relevant to the question. The entities retrieved are added to the question before a new search is performed at the finer passage level. Adding the entities retrieved during this first step makes the question more specific.
This, in turn, ensures that only the most relevant passages are selected, thus providing the answer generation model with additional context. Stated in more formal terms, the principle is to learn the probability p(a|q,z,e) of generating an answer, a, conditional on the question, q, an extracted passage, z, and the corresponding extracted entity, e.
Both the information retrieval model and the answer generation model are involved in this end-to-end learning process.
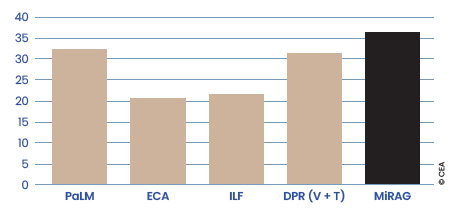
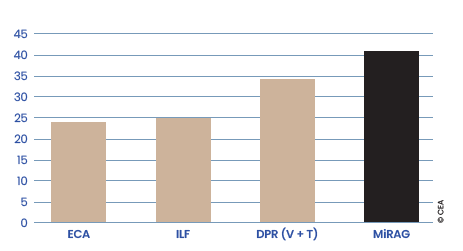
A comparison of MiRAG with reference models combining text and images for the KVQAE task, in this case ECA, ILF, and DPR[V+T], (Figures 1 and 2), shows that combining a RAG-based approach with MiRAG’s multi-level search strategy makes better use of the synergy between the two modalities.
|
|
|