

Conventional inverse kinematics (IK) techniques can provide mathematically exact solutions (if any exist) for determining joint configuration from effector (fingertip) position alone. However, because the positions of gripper fingers’ intermediate phalanges must also be considered, these techniques often require a posteriori decision-making. For more complex kinematics, numerical approximation algorithms, which may not perform as well in dynamic environments, are used.
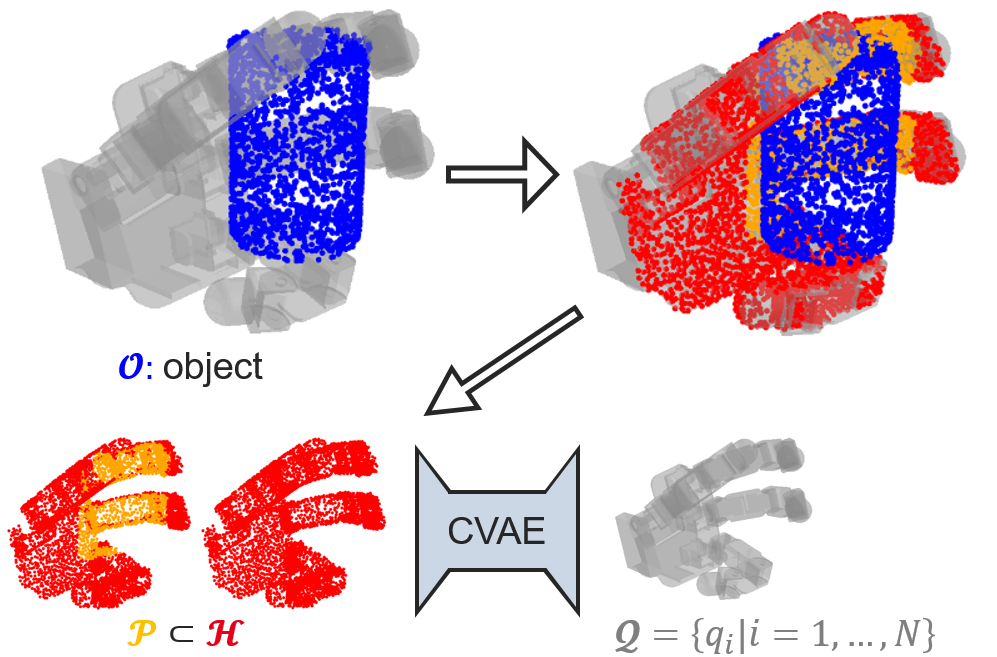
We developed an innovative machine learning method that leverages a conditional variational autoencoder (CVAE) to reconstruct joint configurations from the robotic gripper’s point cloud.

Tests on the MultiDex dataset produced an average joint error of less than 4% with ultra-rapid inference (< 0.05 ms). The algorithm, whose ultra-rapid inference eliminates the need for computationally-costly numerical optimization steps, responds to the demands of real-time environments. Because the training data is generated solely from the URDF model, the method is easy to adapt to any type of gripper.
average joint error with inference time of 0.05 ms (faster than the state of the art) with the MultiDex grip dataset and the Allegro gripper.