


Conventional object detection requires massive, manually-annotated datasets—making the process costly and difficult to upgrade or scale. We are working on an object-discovery approach that would eliminate the need for human supervision. In 2D image analysis, a group of pixels moving along a coherent trajectory is considered a single object. So far, this approach has not been explored extensively for 3D images, mainly due to the gaps in data inherent to LiDAR point clouds.
Using 2D motion, CEA-List developed an initial reference dataset for 3D object discovery (DIOD-3D), and then designed a cross-distillation training framework, xMOD, based on a symmetrical “teacher-student” architecture in which a 2D expert model and the 3D model guide each other’s learning. This reciprocal interaction harnesses the complementarity of the 2D and 3D data, compensating for each modality’s weaknesses. The camera steps in for the LiDAR sensor if there are too few data points, and the LiDAR sensor steps in for the camera in challenging conditions like low light or a lack of texture.
The approach also includes another innovation: scene completion as a pretext task for 3D discovery. The model differs from simple reconstruction in that it is trained to predict denser point clouds for a better understanding of object geometries, even when input data is sparse.
With xMOD, millions of scenes can be labeled with no human intervention. The use of both camera and LiDAR data enhances precision.
The model was tested on one synthetic dataset (TRIP-PD) and two real datasets (KITTI, Paymo), outperforming the state of the art in 2D object discovery, with performance improvements ranging from 8.7 (KITTI) to 15 (Waymo) F1
score points. Further reliability improvements can be achieved using a late fusion strategy, which entails combining the 2D and 3D predictions only during inference. This strategy proves particularly effective for objects at medium distances (10 meters to 30 meters).
These advances in object discovery pave the way for faster, more reliable design of the 3D perception models essential to automated driving systems (ADS).
 |
 |
 |
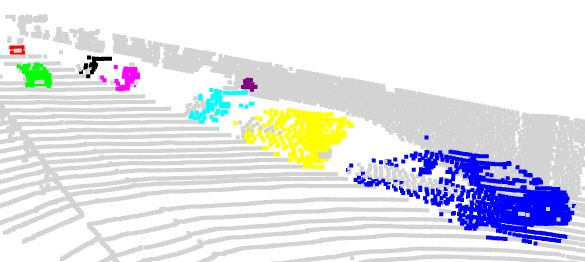 |
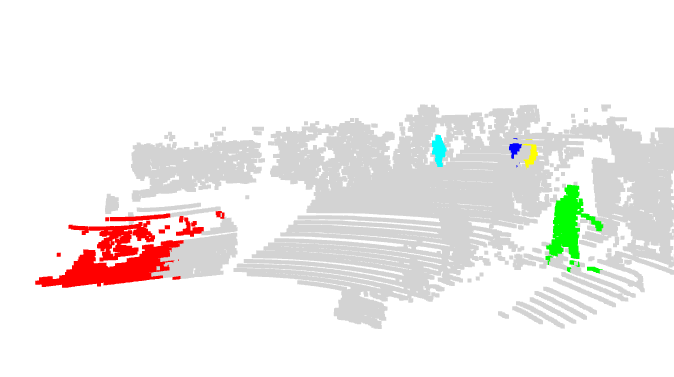
| Figure 2: 3D visualization of xMOD predictions (2D & 3D) | |
15.1: maximum F1@50 score improvement obtained by xMOD compared to the state-of-the-art in 2D object discovery.
Embedded AI processing into smart systems and devices.