


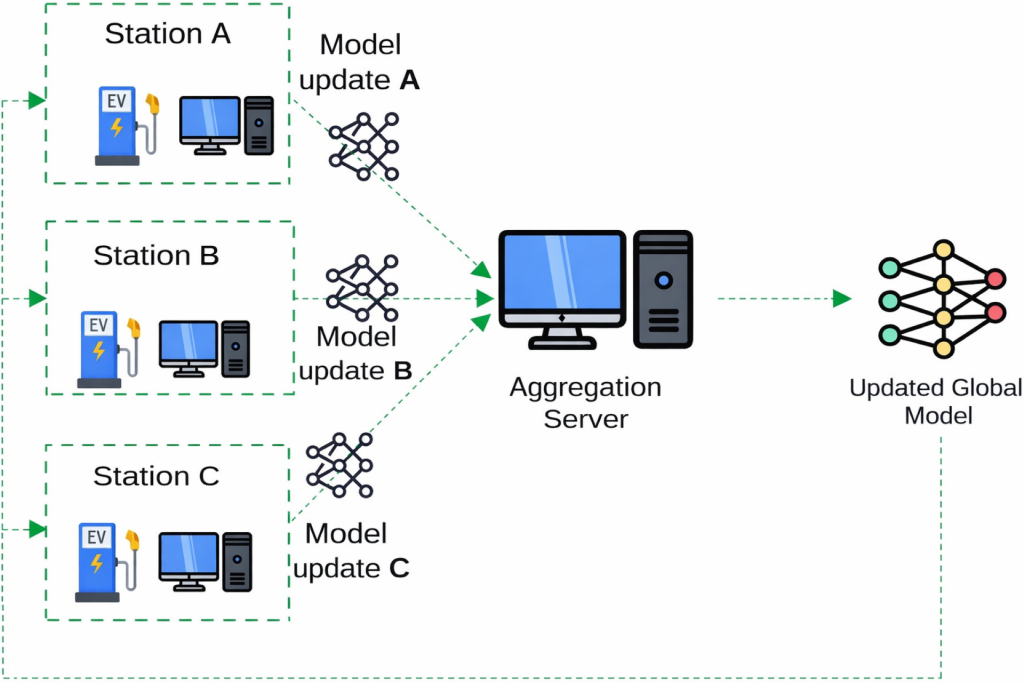
As the energy transition gains traction, the use of distributed energy resources like renewables, electric vehicles, IoT devices, and microgrids is increasing rapidly—multiplying the number of distributed data sources and generating massive amounts of heterogeneous and sometimes-sensitive data. When it comes to processing all this data, centralized data management approaches are reaching their limits in terms of security and privacy. The purpose of the AI-NRGY project (PEPR TASE) is to develop a distributed AI architecture suitable for the very large number of decentralized sources of data and energy that will make up the energy systems of the future. In federated learning (Figure 1), models can be trained collaboratively on distributed data without moving the data, improving data security and privacy. However, when it comes to the processing of time data and continuous data streams, federated learning does present two drawbacks: concept drift (changes in the statistical properties of data over time) and catastrophic forgetting (the loss of previously acquired knowledge when a model is retrained on new data). Our continuous, adaptive federated learning framework efficiently manages concept drift, catastrophic forgetting, and heterogeneous client data.
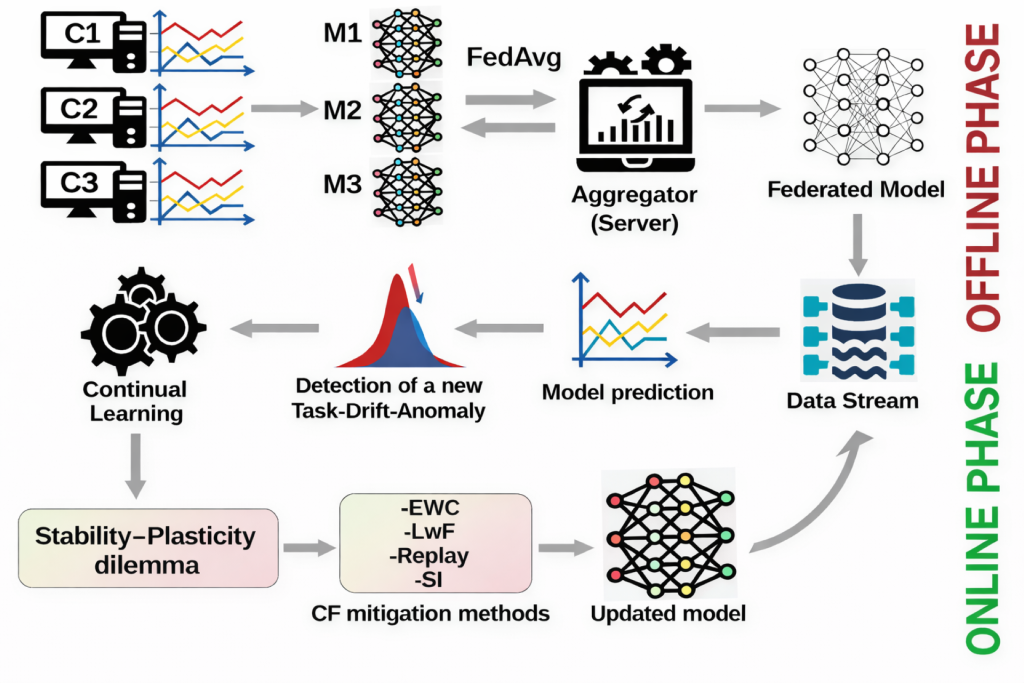
The process is broken down into two phases, one offline and one online (Figure 2). During the offline phase, data is collected, prepared, and pre-processed at each client site. The backbone federated learning model is then trained. During the online phase, data streams are processed in real time, and the trained federated learning model makes predictions. Model performance is evaluated after each prediction. A drift-detection mechanism identifies any changes in data distribution.
If any drift is detected, adaptation techniques based on dynamic clustering and incremental learning are applied to adjust the model to the changing data. Empirical testing demonstrated a significant reduction in prediction errors (up to 30% to 40% compared to reference models) in the presence of concept drift.
Up to a 30% to 40% reduction in prediction errors