With our Cognitive Programming Interface (CPI), non-expert users can program robots by creating a series of sequences consistent with the current state of the scene. The CPI is based on three developments:
In the CPI’s cyclical workflow, the scene is initialized by the world model, which then uses a semantic reasoning engine to calculate the possible skills or abilities. This set of possibilities is sent to the graphical interface and then, according to the actions chosen by the user, the model updates itself. Some steps, such as when a particular relationship or action needs to be specified, may require human intervention.
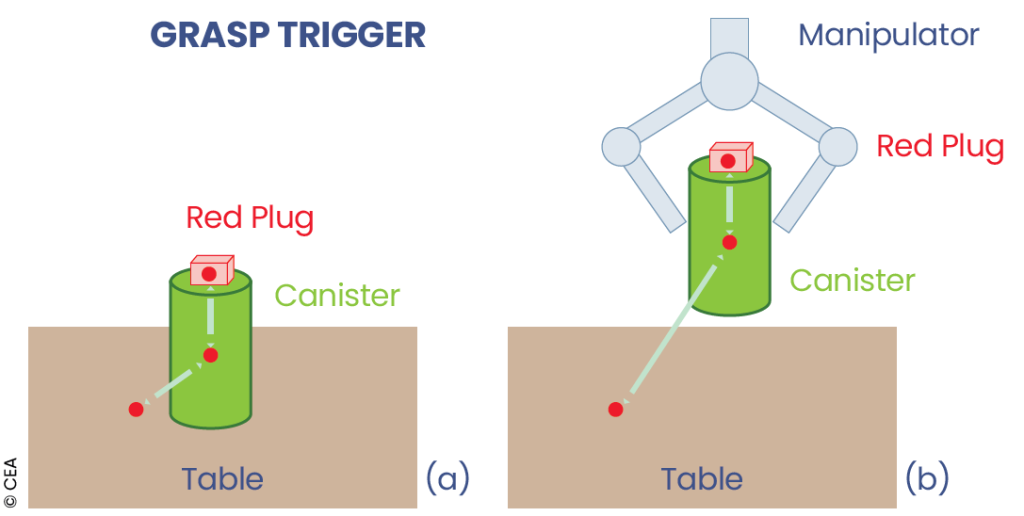
In the ontological model, actors are described by a geometric primitive, their properties, and, particularly, their interfaces, whose relative positions in the object’s frame of reference is known. These interfaces express interaction capabilities (grippable, insertable, placeable, etc.), enabling reasoning not based on objects, but rather on their most likely interactions depending on the context. Relationships between ontology instances are represented as <subject, predicate, object> triplets (e.g.<robot, grasps, object>).
Interaction capabilities are defined by a set of parameters, preconditions, and their effects, which allow relationships to be added, removed, or updated in the ontology. The CPI also allows hybrid queries, which, in the presence of ambiguous or missing information, can call upon either the knowledge base or the user.