

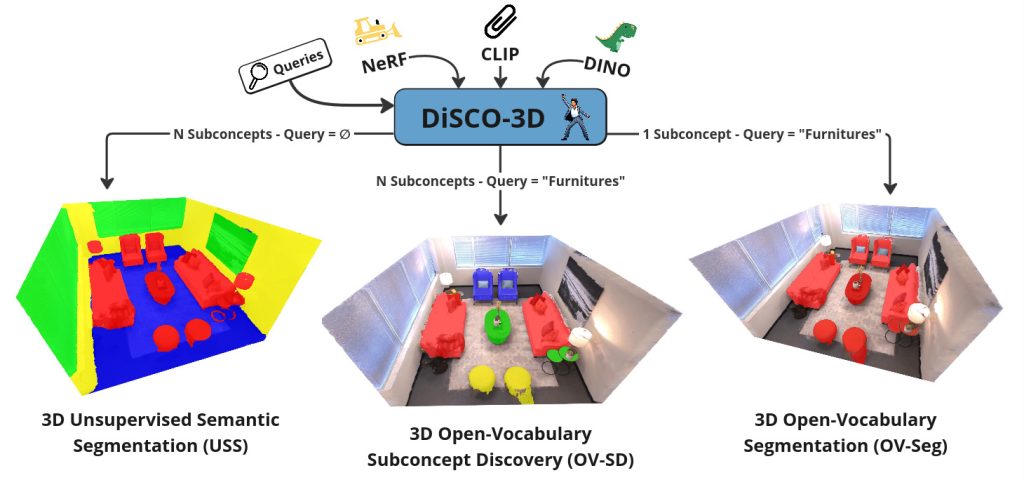
The methods currently used for 3D semantic segmentation either identify objects corresponding to a single semantic concept searched for by the user (open vocabulary segmentation, or OV-Seg) or adapt to the content of the scene by discovering several semantic concepts (unsupervised semantic segmentation, or USS).
The broader problem of open vocabulary sub-concept discovery (OV-SD) is effectively addressed by bringing these two paradigms together, for the first time ever, in DiSCO-3D. The objective is to discover the different semantic sub-concepts in the 3D scene that are relevant to a natural language query (Figure 1).

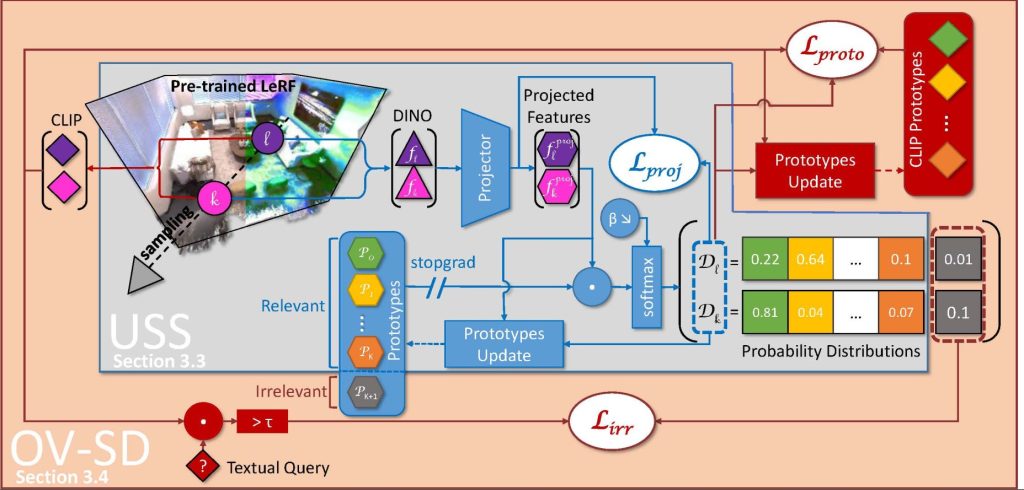
DiSCO-3D’s architecture (Figure 2) is made up of two modules. The first module completes the OV-Seg task to identify areas of the scene that do not correspond to the user’s query (the background). The second module “forces” one of the segments to superimpose on the background identified by the first module, creating the USS. This supervision ensures that the other segments discovered by the USS correspond to semantic subconcepts relevant to the query.
The method proved effective on a variety of user queries on different scenes (Figure 3).

Finally, because the queries are expressed in natural language, DiSCO-3D is easy to integrate as an agentic AI tool. This would make 3D scene analysis using large language models (LLMs) possible.
*NeRF: Neural Radiance Fields are a state-of-the-art technology that uses a neural network to reconstruct 3D scenes from 2D images.
**LeRF: Language Embedded Radiance Fields extend the capabilities of NeRFs by associating semantic information with each point in a scene.