


Data privacy is a major concern when it comes to designing AI systems. This is because the statistical models used in AI are trained on large, previously-labeled datasets—some of which may contain proprietary and/or sensitive data.
Federated learning for collaborative AI model training
With federated learning, multiple stakeholders, both individuals and organizations, can provide access to their datasets to train an AI model. Learning is decentralized and updates to the shared model are aggregated on a central server to be distributed to all contributors. This approach ensures that each contributor’s data remains private.
However, at some point, end users are given access to the AI model trained on the data, raising security issues. A recently-discovered AI security risk—the model inversion attack—could leave training data exposed. A data holder or a bad actor with access to the central server, for example, could potentially reverse engineer the model’s output to determine what the input data was.
Differential privacy for enhanced security
Differential privacy is a technique that prevents bad actors from determining whether specific data (like data that can identify a person) has been used to train the model.
One of the most used differential privacy methods is random noise generation, either by the aggregation server before the model is sent, or by the end user. The downside is decreased model performance and, specifically, less accurate predictions. CEA-List’s research has focused on achieving a better tradeoff between data privacy and AI model accuracy.
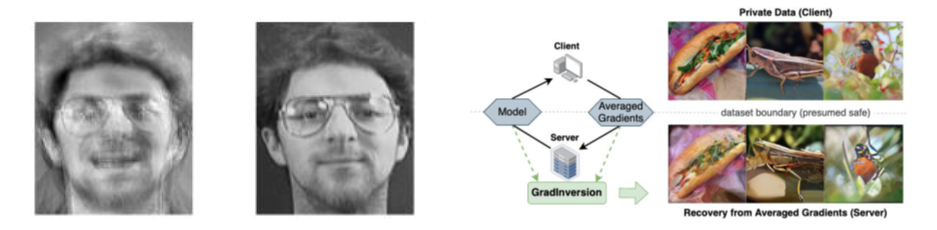
Images reconstructed using an inversion attack:
Left: The image reconstructed from the model (left), compared to a copy of the image in the training dataset (right), unknown to the attacker.
Right: This is a second type of attack that targets the gradients exchanged at each learning iteration. The attacker can very faithfully reconstruct the input data from the gradients, again with no direct knowledge of the original data.
CEA-List’s new federated learning framework, SPEED, improves the privacy-accuracy tradeoff. The research that led to the advance was published in the journal Machine Learning2. In this framework, the end users are not considered trusted agents, and neither is the central server. The framework is based on a voting system. A simplified version of the model is trained on the end user’s private data. The server then sends an unlabeled data instance, and the end user’s simplified model yields an estimated label of the instance, called a vote.
SPEED uses homomorphic encryption to process the votes anonymously. End users encrypt their votes, and the server aggregates them without decrypting them. This means that the server cannot access individual votes. The framework was applied to test models, and performed at the state of the art. For example, SPEED protected the server data without sacrificing model accuracy, something that PATE3, another differential privacy framework, cannot do.
Homomorphic encryption uses approximate algorithms. As their name suggests, these algorithms produce approximate—but not exact—solutions. Quantization must be used to map continuous data into discrete datasets. This process introduces “natural” noise into the data, much like a rounding error. CEA-List researchers recently found theoretical proof that quantization does indeed introduce this noise.
SHIELD is deliberately approximative, thereby reducing the algorithm’s computational burden while still ensuring differential privacy4.
SPEED and SHIELD could find their niches in healthcare, biometrics, and any other market where personal, sensitive, or proprietary data needs to be kept private. The potential is vast.
The solutions developed at CEA-List are already being used to increase the privacy of facial recognition systems, which typically require large training datasets that are often provided by organizations.
“We are now looking to expand into an even broader range of use cases, like cybersecurity, through EU-backed projects. When used together, the techniques we have developed could enable the secure sharing of data signatures, for example. This kind of solution could be extremely useful to public-sector organizations like government agencies that deal with threats daily. But the private sector is also showing increasing interest. We are talking to more and more businesses about how they can seize opportunities to extract value from their sensitive data without compromising on data privacy.”
1. Yin, H., Malya, A. Vahdat et al (2021), See through Gradients: Image Batch Recovery via GradInversion. arxiv:2104.07586
2. Grivet Sébert, A., Pinot, R., Zuber, M. et al (2021). SPEED: secure, PrivatE, and efficient deep learning. Machine Learning 110, 675–694.
3. Papernot, N., Abadi, M., Erlingsson, U., Goodfellow, I., & Talwar, K. (2017). Semi-supervised knowl-edge transfer for deep learning from private training data. 5th international conference on learning representations.
4. Grivet Sébert, A., Zuber, M., Stan, O. et al (2023). When approximate design for fast homomorphic computation provides differential privacy guarantees. arxiv:2304.02959


