


The focus of the EvalLLM 2024 challenge was to evaluate neural-network-based models for named-entity recognition (NER), a cornerstone task of information extraction. This evaluation was carried out in a few-shot setting (in French, where there is much less available annotated data than in English). In real-world information extraction, it is very rare to have enough annotated data to adapt traditional supervised learning models. For this reason, participants only had four newsletters and a blog post to work with.
The most pressing issue is whether large generative language models are better than much smaller encoder-type language models for few-shot environments of this kind. To find out, the CEA researchers used two models: GoLLIE (Sainz et al., 2024) and GLiNER (Zaratiana et al., 2024). GoLLIE, based on the Code-LLaMA 13B generative model, turns the named-entity recognition task into a code-generation task via prompts similar to Figure 2:

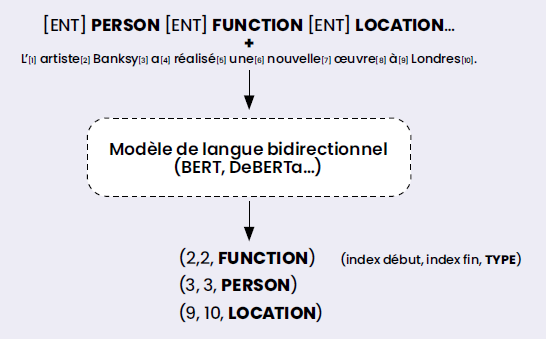
Both models are pre-trained on a large scale using English-language datasets unrelated to the target domain of the evaluation. For GoLLIE the training data was manually annotated; for GLiNER it was automatically generated using ChatGPT.
GLiNER clearly outperformed GoLLIE on the evaluation task, with a gain of 62% on the macro-F1 evaluation and 118.6% on the micro-F1 evaluation.
It also outperformed the—much larger—GPT-4o model used by the team that came in second in the challenge (Figure 4).
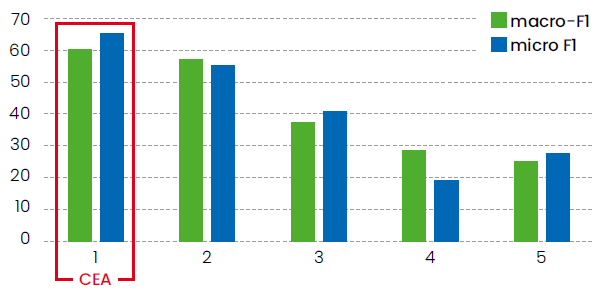
As part of EU-funded projects in progress, we are investigating how to apply the results obtained for this competition to safety data. And, as part of the French national AI initiative’s Sharp project on frugal AI, we are looking for ways to improve the few-shot performance of the GLiNER model.
When it comes to AI image generation, impressive results can be achieved with text-conditional models like Stable Diffusion. However, their capacity to take into account text-based instructions is not always evaluated precisely. We developed a new metric (the Text-Image Alignment Metric, or TIAM) that is based on two key elements: the controlled generation of text-based prompts and image analysis.
The goal is to determine how well a model adheres to the number of objects or color specified. We studied the six most commonly-used existing AI models to demonstrate their still-limited ability to follow a prompt that involves more than one object. This ability is even more limited when the prompt includes a color.TIAM is a useful tool for studying the influence of AI training parameters on the comprehension of and compliance with prompts. It also paves the way toward new research on noise mining—techniques to identify the “right” noises with a view to improving AI output.
The CEA is contributing its research on few-shot namedentity recognition models to the EU VANGUARD, ARIEN, and STARLIGHT projects, which address the field of security. Ultimately, these models could be used to scan text on social media for signs of criminal activity.
“CEA-List@EvalLLM2024: prompter un très grand modèle de langue ou affiner un plus petit ?” Robin Armingaud, Arthur Peuvot, Romaric Besançon, Olivier Ferret, Sondes Souihi and Julien Tourille EvalLLM2024 : Atelier sur l’évaluation des modèles génératifs (LLM) et challenge d’extraction d’information few-shot, Toulouse, France
