


In physics and molecular chemistry, algebraic operations— used massively for Big Data analysis—account for 80% of high-performance compute time. Another issue is the use of limited-precision floating-point arithmetic encoded in 32 or 64 bits, which means that as problems get larger, rounding errors increase. This can make calculations much, much longer—or even impossible—to complete. Preconditioners applied to the compute kernels to compensate for this also add complexity and increase the necessary memory resources.
Augmented-precision arithmetic can be used to reduce rounding errors, ensuring the convergence of calculations and, in all cases, reducing the number of iterations required to complete the calculations by between a factor of two and a factor of five. Until now, however, software emulators—too slow for real calculations—were the only way to take advantage of extended precision.
VxP is the first generic processor to natively support extended-precision arithmetic up to 512 bits of mantissa, with performance comparable to that of 64-bit operations (with 53 bits of mantissa) on conventional processors. The VxP is a RISC-V processor augmented with support for extended precision arithmetic and memory access. The processor is designed to take over from generic 64-bit processors in high-performance compute nodes for problems that require a higher level of precision. The handover does not require resource-intensive copying or transcoding of data because the processors share the same memory within the compute node.
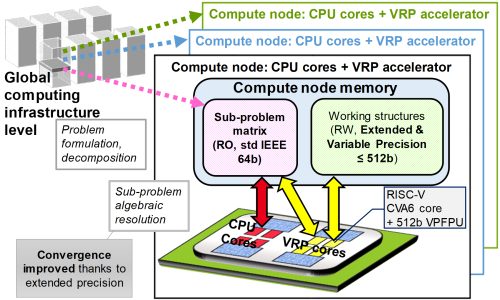
The 2023 prototype was built on a chip manufactured using GlobalFoundries’ 22FDX® platform. This prototype version delivers an acceleration factor of up to 24 on iterative Krylov space solvers (at the state of the art) compared to a software emulation of the extended precision.
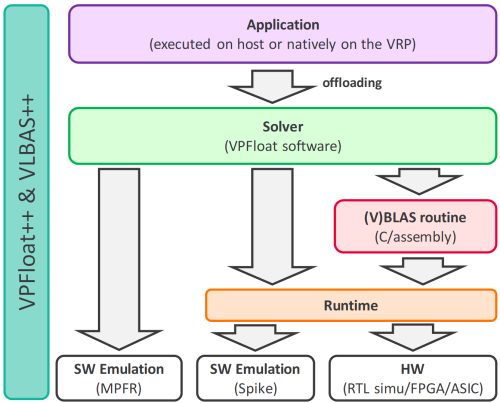
VxP is primarily intended for computational physics, molecular chemistry, structural calculations, medical imaging, climate models, fluidics, and other scientific computing needs. It can also be used to train AIs and calculate system dynamics.
“Procédé et dispositif de représentation en virgule flottante avec précision variable.” Publication/patent number: FR3093571B1. Publication date: March 19, 2021.
The new-generation VxP accelerator will be integrated into French startup SiPearl’s Rhea processor developed under the European Processor Initiative launched in November 2018. The initiative, which involves Europe’s main HPC stakeholders, will result in the next European exascale computing processor. Rhea will be integrated into the future Jupiter supercomputer located at Jülich in Munich.
