


Google’s OSS-Fuzz, which is just one of many public fuzzing platforms, contains tens of thousands of bugs—a number most development teams cannot even hope to keep up with. But the sheer number of vulnerabilities is not the only challenge. The reports generated by automated vulnerability detection tools provide little information about the security impacts of the vulnerabilities detected. This makes it practically impossible to prioritize the most dangerous vulnerabilities so that they can be corrected quickly. The need for automated vulnerability and exploitability testing techniques has never been greater.
Our research introduces a formal expression of the exploitability of a given vulnerability to tell us how likely it is that an attacker will be able to influence the behavior of a certain kind of vulnerability through program inputs. Intuitively, a vulnerability whose effects on a program can be finely controlled by an attacker is more dangerous that a vulnerability that is less exploitable. Our formal evaluation technique measures the number of unique behaviors that an attacker can control. But knowing the number of behaviors is only part of the solution. You must also be able to determine how dangerous the behaviors are. Our approach is to include all this information to arrive at a priority score—a unique and complex challenge. Formal methods ensure that the results are transparent and explainable. However, they can also be used to explore areas that have only rarely been addressed by researchers until now. And, in the limited esearch that does exist, the methods used always rely on either an expert’s judgment or on a rough classification that assumes all vulnerabilities in a class are equally dangerous.
Our research was published in the proceedings of Usenix Security 2025, one of the world’s leading scientific conferences on security (A-rank*). It also resulted in a platform. We tested and validated our approach on verification tasks involving real memory corruption vulnerabilities taken from CVEs (Common Vulnerabilities and Exposures databases) and on a benchmark of vulnerabilities detected by Google’s OSS-Fuzz. Our assessment covered a wide range of programs from widely used libraries like libxml2 and libpng, large-scale complex systems like openssl, and the universal bootloader u-boot, for example. Our approach produced a relevant classification of the danger of different vulnerabilities, establishing a new state of the art.
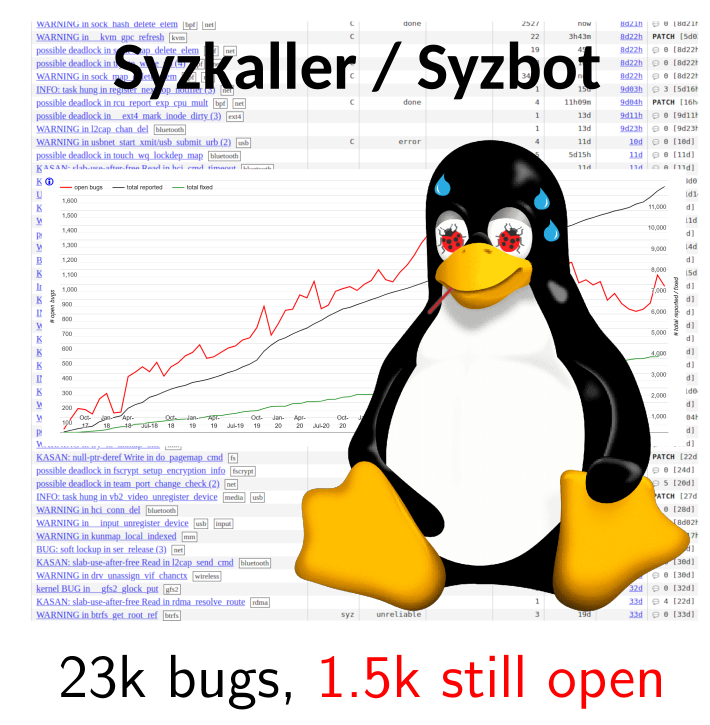
Syzbot (Linux):
1,500+ vulnerabilities still open.
OSS Fuzz (Google):
4,000+ vulnerabilities still open.
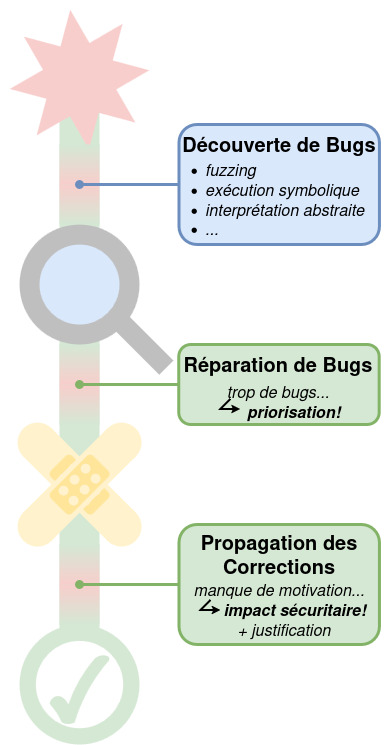
Today’s verification tools identify far more vulnerabilities than what can be corrected. So, how do you know where to begin? By using formal methods, vulnerabilities can be prioritized according to how dangerous they are.»