


Le framework Cognitive Programming Interface (CPI) aide un utilisateur non expert à programmer un robot, en lui donnant la possibilité d’enchaîner des séquences cohérentes avec l’état courant de la scène. Cette interface repose sur trois éléments :
Le workflow de la CPI est cyclique : le modèle du monde initialise la scène, calcule les compétences ou aptitudes possibles via un raisonneur sémantique, transmet l’ensemble des possibilités à l’interface graphique, puis se met à jour en fonction des actions choisies par l’utilisateur. Certaines étapes peuvent demander une intervention humaine, notamment lorsqu’une relation ou une action particulière doit être précisée.
Dans le modèle ontologique, les acteurs sont décrits par une primitive géométrique, leurs propriétés et plus particulièrement leurs interfaces dont on connait la position relative dans le référentiel de l’objet. Ces interfaces traduisent des capacités d’interaction (Attrapable, Insérable, Plaçable, etc.) et permettent de raisonner non plus sur les objets mais sur leurs interactions les plus probables en fonction du contexte. Les relations entre les différentes instances de l’ontologie sont représentées sous la forme de triplets <sujet, prédicat, objet> (par exemple <robot, grasps, object>).Les capacités ou aptitudes d’interactions sont définies par un ensemble de paramètres, des préconditions ainsi que leurs effets qui permettront d’ajouter, retirer ou mettre à jour des relations dans l’ontologie. Il existe aussi des requêtes hybrides, capables de solliciter soit la base de connaissances soit l’utilisateur en cas d’ambiguïté ou d’information manquante.
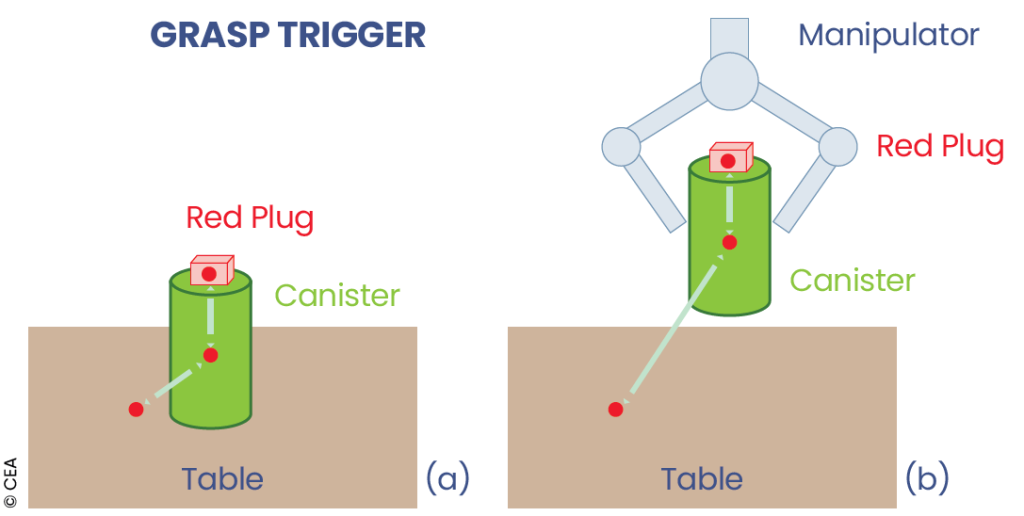
Un module de reconnaissance d’interactions par démonstration est utilisé afin de déduire automatiquement, lors d’une démonstration kinesthésique (réalisée à la main par l’opérateur), la suite de compétences ou aptitudes exécutées. On fait pour cela l’hypothèse que chaque compétence débute ou s’achève par un changement d’état du préhenseur. Deux fonctions principales — TriggerGrasp et TriggerRelease — interprètent les mouvements, les contacts et les relations entre objets afin d’actualiser l’état sémantique du monde. Un algorithme identifie ensuite le type de compétence grâce aux prédicats modifiés, puis en déduit les paramètres exacts en comparant les changements observés avec les effets attendus des compétences possibles.

Ce projet traite de la traçabilité et de l’automatisation des processus industriels de contrôle de la stérilité dans l’industrie médicale et pharmaceutique.
Deux robots UR10e ont manipulé deux conteneurs disposés sur leur support. L’expérience valide la reconnaissance automatique de compétences à partir d’une démonstration kinesthésique. Dans la démonstration, l’opérateur exécute quatre actions : la saisie puis l’insertion successive des deux conteneurs dans l’un des emplacements du support. A chaque changement d’état, le système a su correctement identifier chaque type de compétence et ses paramètres associés (objet, robot, emplacement) en comparant les changements sémantiques observés à ceux attendus. La séquence complète est reconstruite fidèlement et visualisée dans l’interface, montrant la robustesse de l’approche. Il devient alors possible de répéter cette action de manière automatique avec le robot.