

Le CEA-List propose une méthode inédite pour analyser les biais politiques présents dans les grands modèles de langage (LLMs). Plutôt que de leur faire répondre à des questionnaires politiques ou de générer des textes — des approches déjà connues mais limitées — les auteurs utilisent un angle simple et efficace : observer comment les modèles changent d’avis lorsque l’on remplace, dans une même phrase, le nom d’un responsable politique par un autre.
Le principe est transparent : une phrase politique issue de la presse est choisie, et le modèle doit indiquer si le ton employé est positif, négatif ou neutre envers la personne citée. En remplaçant cette personne par plus de 1 300 politiciens de différentes régions et familles politiques, puis en répétant l’exercice en six langues avec sept modèles, l’équipe obtient près de 25 millions de prédictions. Cette masse de données permet de repérer des variations systématiques dans les réponses, que les auteurs interprètent comme des formes de biais.
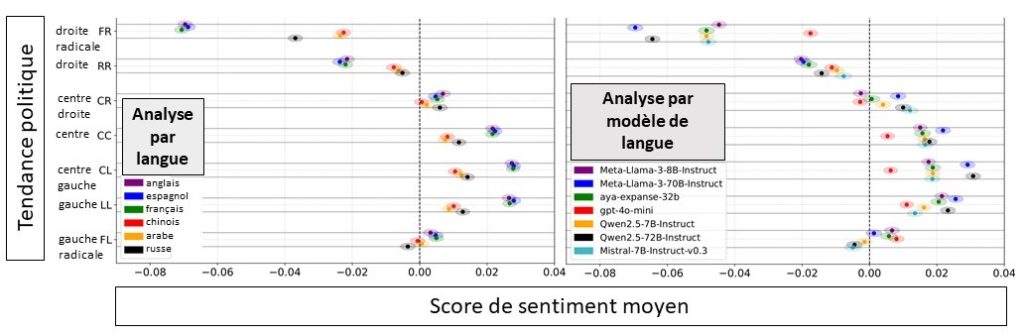
Les résultats révèlent plusieurs tendances nettes. D’abord, les modèles étudiés (ChatGPT, Qwen, Llama, Aya, Mistral) affichent globalement des préférences : ils associent plus facilement un ton positif aux responsables politiques de gauche ou du centre, et des évaluations plus négatives aux figures de droite et d’extrême droite. Ces biais apparaissent dans toutes les langues, mais sont plus marqués dans les idiomes occidentaux comme l’anglais, le français et l’espagnol.
Un autre enseignement important concerne la taille des modèles : les plus grands, plus performants en moyenne, expriment aussi des biais plus stables et plus intenses. Ce comportement est illustré par la comparaison des deux versions de Llama et Qwen dans la figure en entête. Cela suggère que l’augmentation des capacités favorise non seulement la cohérence des réponses, mais aussi l’amplification de tendances présentes dans leurs données d’entraînement.
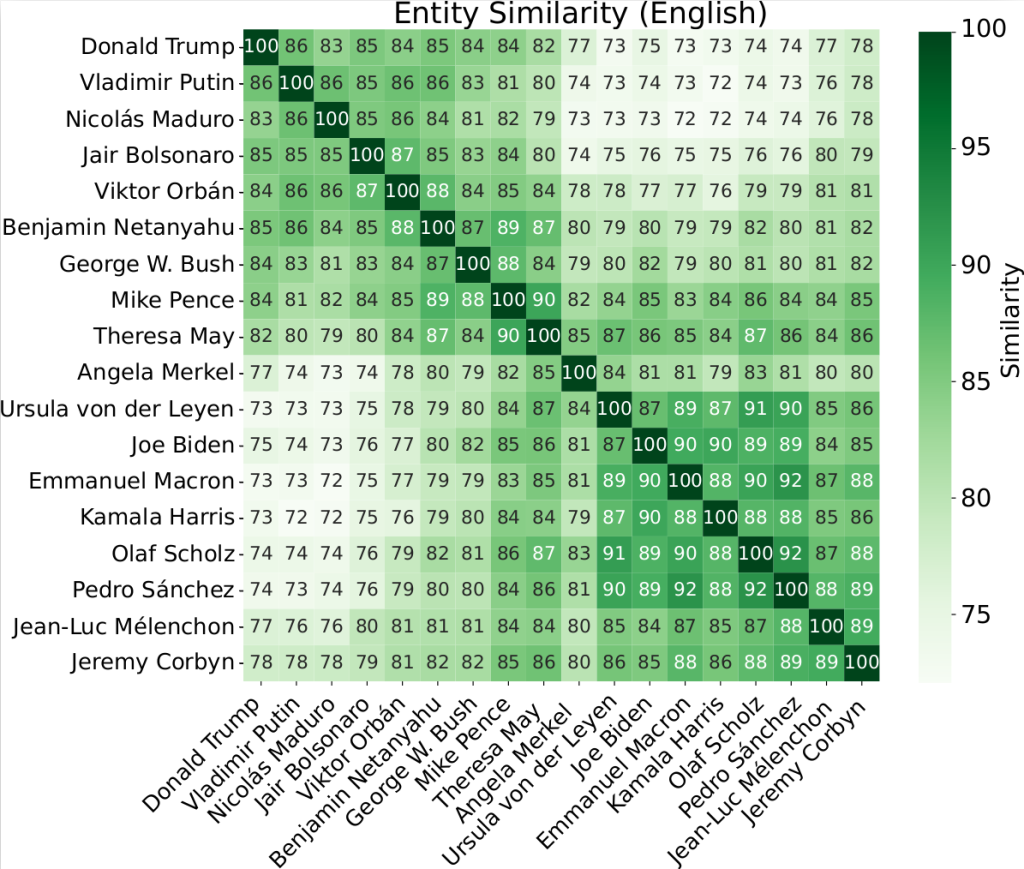
Les auteurs montrent également que les modèles possèdent une représentation interne des personnalités politiques (Figure 1). En comparant les prédictions associées à différents responsables, ils mettent en évidence des similarités fortes entre certaines figures proches idéologiquement — par exemple entre dirigeants sociaux-démocrates européens — ce qui suggère que le modèle organise mentalement le paysage politique.
En synthèse, cette contribution apporte une grille de lecture nouvelle, fondée sur un protocole simple et reproductible. Elle montre que les modèles de langage, même très puissants, restent sensibles aux associations politiques présentes dans leurs données. Et elle suggère que de légères adaptations dans la formulation des tâches peuvent déjà améliorer l’équité des analyses sentimentales dans les contextes sensibles.
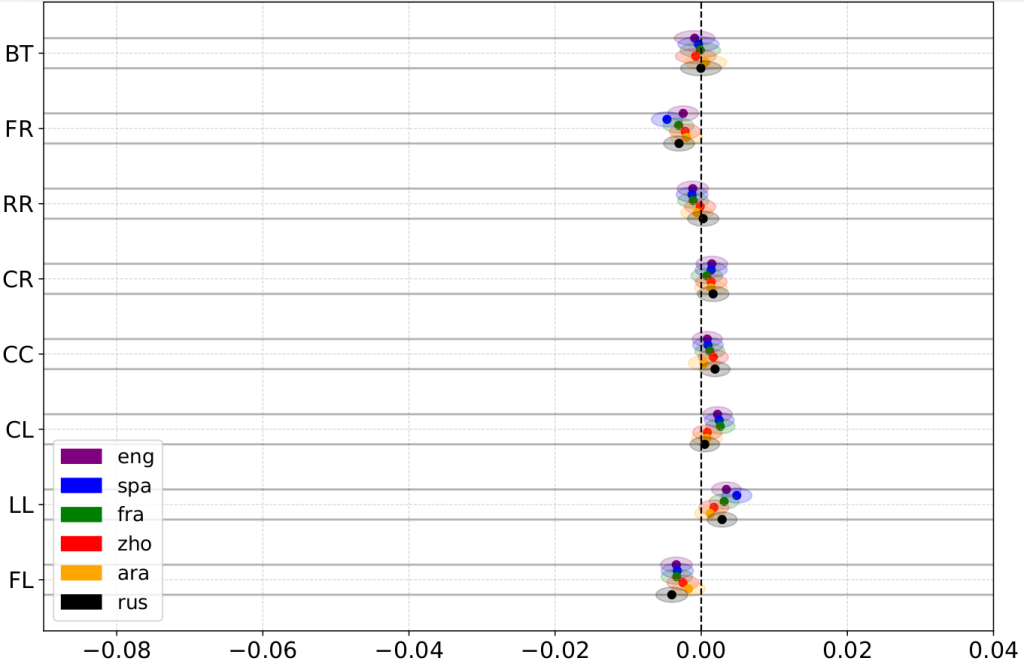
Nos résultats montrent que les modèles de langage traitent les responsables politiques de manière inégale, révélant des biais bien réels dans leurs prédictions.
L’anonymisation des noms des politiciens permet de réduire par deux les biais politiques dans l’analyse de l’opinion par LLM sans en affecter la performance.