


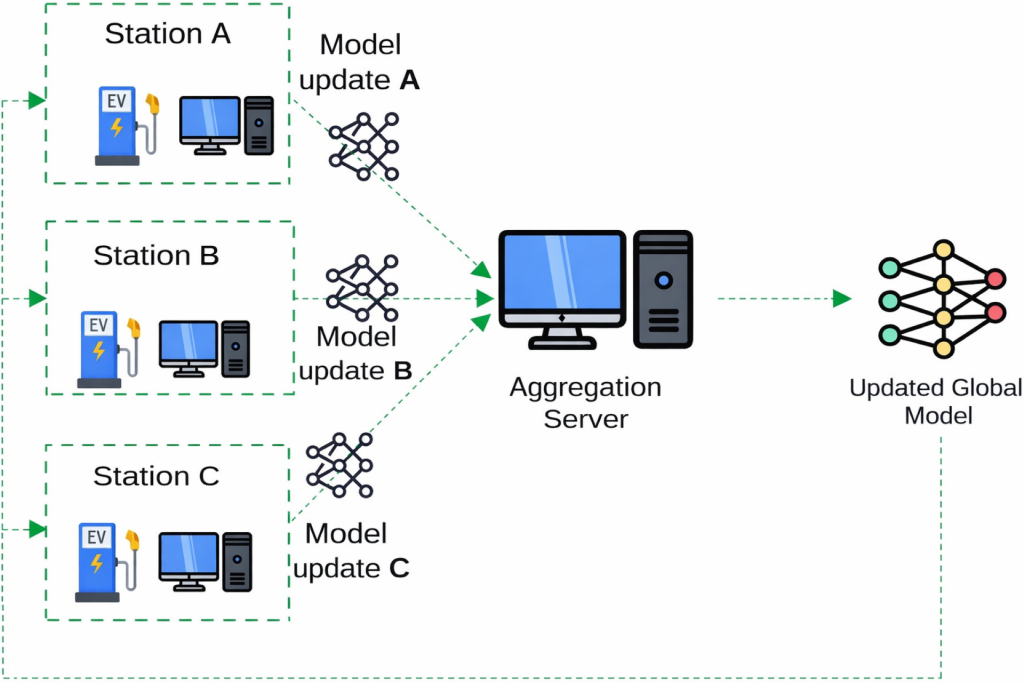
La transition énergétique entraîne une croissance massive des ressources énergétiques distribuées (énergies renouvelables, véhicules électriques, capteurs IoT, micro-réseaux). Ces systèmes génèrent des données massives, hétérogènes, distribuées et sensibles. Les approches centralisées montrent leurs limites pour traiter ces données de manière sécurisée et respectueuse de la confidentialité. Le projet AI-NRGY (PEPR TASE) vise à développer une architecture d’intelligence artificielle distribuée pour les systèmes énergétiques du futur, qui devront être capables d’intégrer un très grand nombre de sources décentralisées de données et d’énergie. L’apprentissage fédéré, comme illustré dans la figure 1, permet l’entraînement collaboratif de modèles sur des données distribuées sans déplacer les données, améliorant ainsi la confidentialité et la protection des données. Les dérives de concept (les changements dans les propriétés statistiques des données au fil du temps) et l’oubli catastrophique (la perte des connaissances précédemment acquises lorsqu’un modèle est réentraîné sur de nouvelles données) constituent des défis majeurs pour le traitement de données temporelles et de flux continus. Nous avons développé un framework d’apprentissage fédéré continu et adaptatif, capable de gérer efficacement les dérives de concept, l’oubli catastrophique et l’hétérogénéité des données clients.
La méthode proposée se compose de deux phases principales : la phase hors ligne (offline phase) et la phase en ligne (online phase), comme illustré dans la figure 2. La phase hors ligne comprend la collecte, la préparation et le prétraitement des données sur chaque site client, suivis de l’entraînement du modèle d’apprentissage fédéré de base (backbone FL model). La phase en ligne traite ensuite les flux de données en temps réel, applique le modèle fédéré entraîné pour effectuer des prédictions, évalue les performances du modèle après chaque prédiction et intègre un mécanisme de détection de dérive afin d’identifier les changements dans la distribution des données. Lorsqu’une dérive est détectée, des techniques d’adaptation (basées sur un clustering dynamique et un apprentissage incrémental) sont appliquées pour ajuster le modèle aux données évolutives. Les évaluations empiriques ont montré une réduction significative des erreurs de prédiction face aux dérives de concept, jusqu’à 30 à 40 % comparativement aux méthodes de référence.
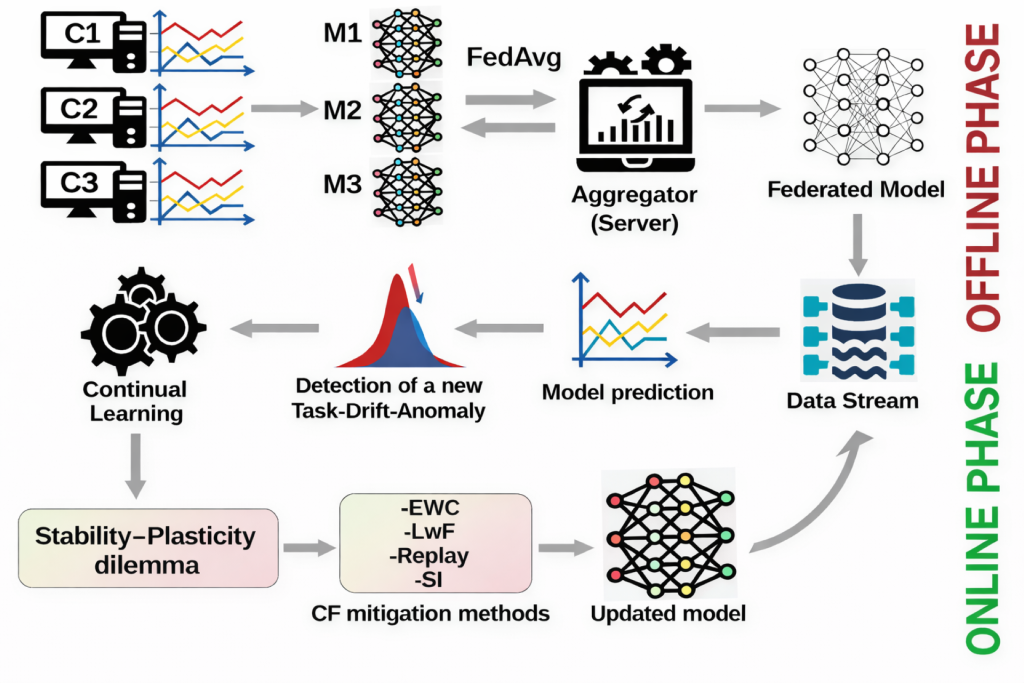
Jusqu’à 30-40 % de diminution d’erreurs de prévision