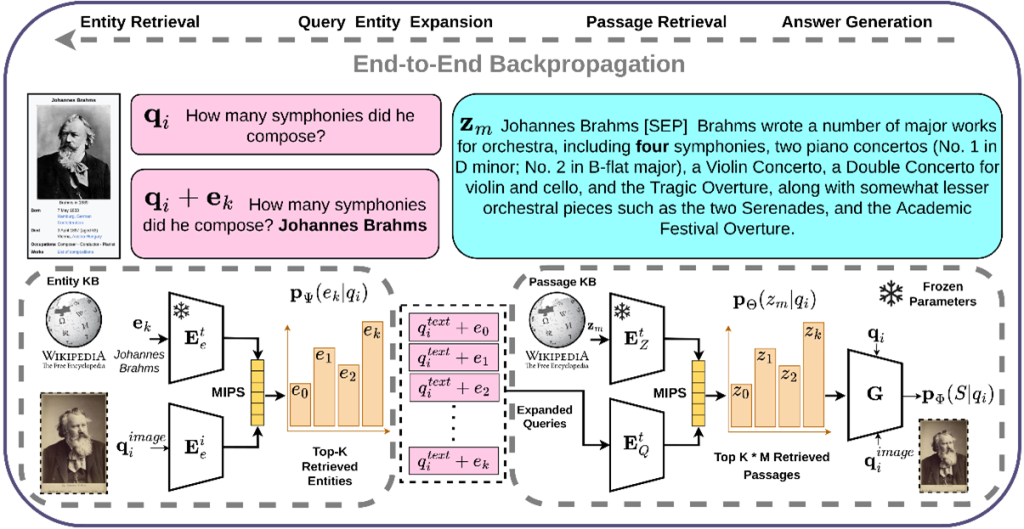
La réponse à des questions visuelles à propos d’entités nommées (KVQAE) a récemment fait l’objet d’une attention particulière en tant que tâche de référence pour évaluer les capacités des systèmes de recherche d’information à comprendre en profondeur les informations visuelles et textuelles. Alors que dans la tâche standard de question-réponse visuelle (VQA), la réponse aux questions peut se faire uniquement à partir des images, la KQVAE impose la recherche des réponses dans une base de connaissances externes constituée à la fois de textes et d’images. Comme l’illustre la figure en entête, un système de KQVAE prend en entrée une question textuelle (combien de symphonies a-t-il composé ?) et une image (une photo de Johannes Brahms) et doit en chercher la réponse dans un ensemble de documents mêlant texte et images (des pages Wikipédia).
Dans ce contexte, le CEA-List a proposé le modèle MiRAG, s’appuyant sur le paradigme du RAG pour résoudre la tâche KVQAE, en associant un modèle de recherche d’information et un modèle de génération des réponses. La figure en entête illustre les principales étapes de cette approche. L’idée de base est d’effectuer la recherche à différents niveaux de granularité (entité et passage) à partir d’une requête multimodale avec des entrées textuelles et visuelles. Cette stratégie d’extraction à plusieurs niveaux affine progressivement la requête avant de générer des réponses à l’aide d’un modèle de génération.
La recherche est d’abord effectuée à un premier niveau, celui des entités, assimilable au niveau des documents, afin d’identifier un ensemble d’entités candidates pertinentes pour la requête. Les entités ainsi récupérées sont ajoutées à la requête avant d’effectuer une nouvelle recherche à un niveau plus fin, celui du passage. L’ajout d’entités aux requêtes permet de spécifier de façon plus précise ces dernières, ce qui aboutit à la sélection de passages plus pertinents et fournit un contexte supplémentaire au générateur de réponses. Formellement, l’objectif est d’apprendre la probabilité p(a|q,z,e) de générer une réponse a conditionnée par la requête q, un passage extrait z et l’entité extraite correspondante e. Cet apprentissage est réalisé de bout-en-bout en associant à la fois le modèle de recherche d’information et le modèle de génération des réponses.
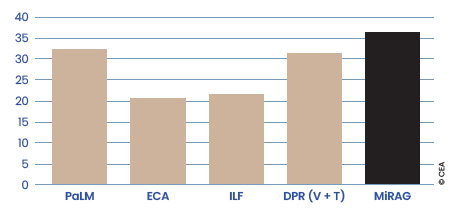
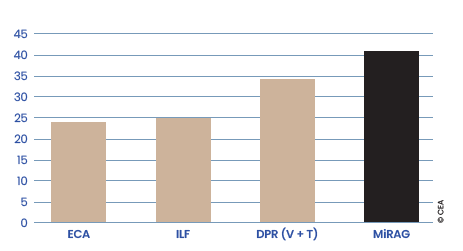
La comparaison de MiRAG à des modèles de référence associant texte et image pour la tâche de KVQAE (cf. Figures 1 et 2), en l’occurrence ECA, ILF et DPR[V+T], montre que conjuguer une approche RAG et la stratégie de recherche à plusieurs niveaux implémentée par MiRAG permet une meilleure exploitation de la synergie entre les deux modalités.
|
|
|