

Comprendre le défi : s’adapter à des données hétérogènes et dispersées
L’adaptation de domaine multi-source (MSDA) répond à un enjeu central : permettre à un modèle d’exploiter plusieurs sources de données hétérogènes pour généraliser vers un domaine cible non annoté. Dans de nombreuses applications industrielles, les données sont non seulement différentes d’un site à l’autre, mais aussi souvent impossibles à centraliser. Le décalage de distribution entre sources et cible dégrade fortement les performances des modèles classiques, qui supposent une homogénéité rarement observée dans la réalité.
Les limites du fédéré classique : un serveur central qui fragilise tout le système
Les approches fédérées récentes ont tenté d’adapter la MSDA au contexte distribué en préservant la confidentialité des données. Toutefois, elles reposent presque toutes sur un serveur central chargé d’agréger et de synchroniser les modèles locaux. Ce fonctionnement introduit plusieurs faiblesses : dépendance à un point unique, risques accrus en cybersécurité et coût de communication élevé.
Notre proposition : un apprentissage totalement pair-à-pair
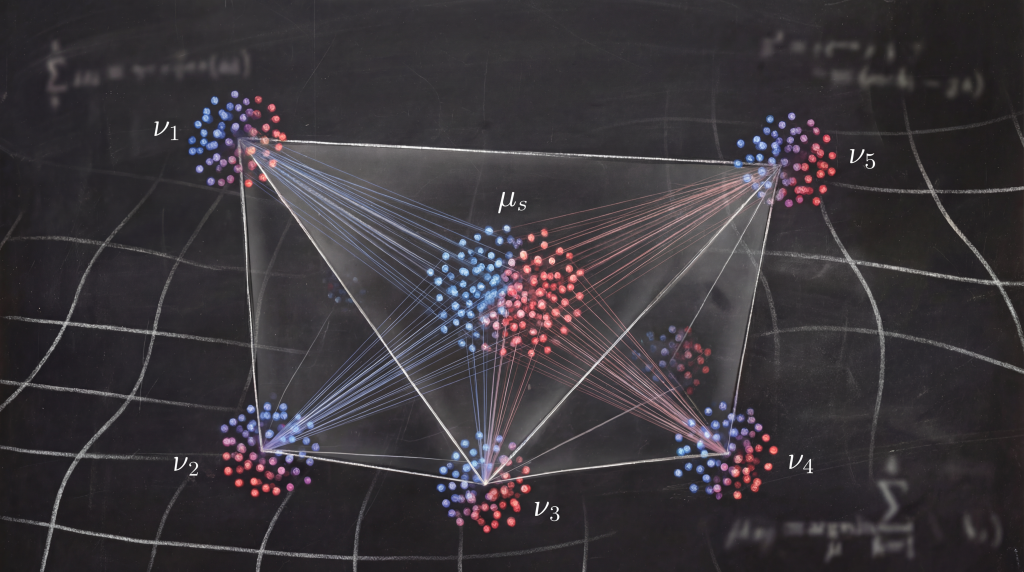
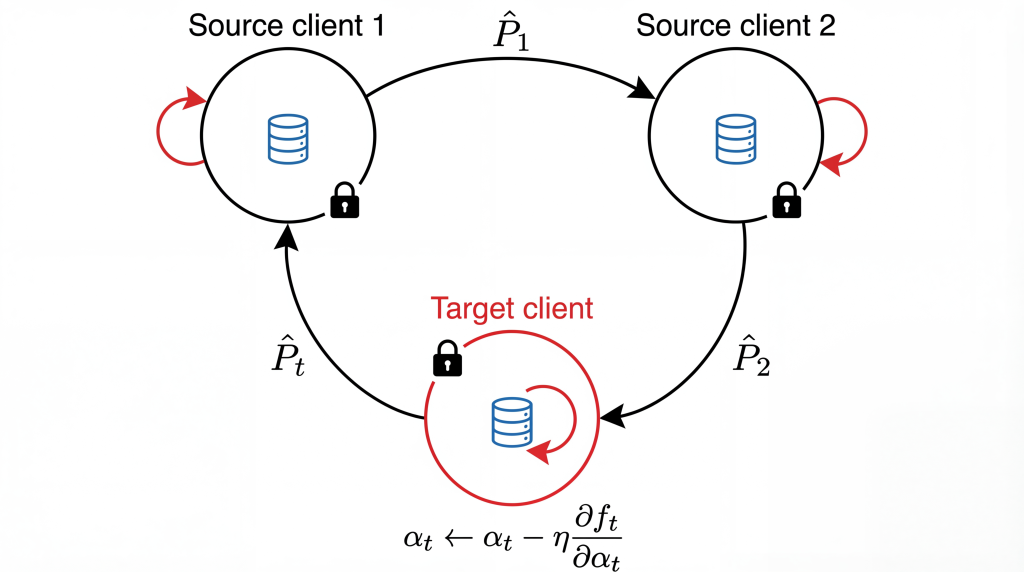
De-FedDaDiL élimine le serveur central. Chaque client conserve une version locale de son dictionnaire d’atomes — éléments fondamentaux permettant de modéliser les distributions — et échange régulièrement ces informations avec un pair tiré aléatoirement. Les atomes reçus sont fusionnés avec ceux du client via une agrégation simple mais efficace, puis optimisés localement. Les coordonnées barycentriques, qui encodent la façon dont chaque domaine se projette sur les atomes, restent strictement privées, garantissant une confidentialité renforcée (Figure 1).
Des performances qui rivalisent avec les méthodes fédérées de référence
Les évaluations menées sur ImageCLEF, Office-31 et Office-Home montrent que De-FedDaDiL atteint des performances équivalentes, et parfois supérieures, à FedDaDiL, la version fédérée centralisée. Sur ImageCLEF, il se place même en tête des méthodes testées. Les résultats indiquent une perte de performance inférieure à 2 % par rapport aux approches avec serveur, tout en réduisant de moitié le nombre d’échanges. L’analyse de la convergence entre clients révèle une diminution progressive de la distance de Wasserstein entre barycentres, attestant d’un alignement naturel malgré la décentralisation totale.