


La détection d’objets classique repose sur des données massivement annotées manuellement, un processus coûteux et peu évolutif. L’approche par la « découverte d’objets » vise à s’affranchir de cette supervision humaine. Appliqué à l’analyse d’images 2D, le principe est de considérer un groupe de pixels se déplaçant avec une trajectoire cohérente comme un seul et même objet. Cette approche restait jusqu’ici peu explorée dans le domaine de la 3D, en raison de la nature éparse et incomplète des nuages de points LiDAR.
Pour répondre à ce défi, le CEA-List a proposé une première base de référence pour la découverte d’objets 3D utilisant le mouvement 2D (DIOD-3D), et conçu xMOD, un cadre d’entraînement par distillation croisée. xMOD repose sur une architecture « enseignant-élève » symétrique : un modèle expert 2D guide l’apprentissage du modèle 3D, et réciproquement. Cette double interaction exploite la complémentarité des modalités de données et permet de pallier les faiblesses de chacune d’elles : la caméra aide le LiDAR lorsque les points sont trop rares, et le LiDAR aide la caméra dans des conditions visuelles difficiles (nuit, manque de texture…).
Une autre innovation réside dans la complétion de scène comme tâche prétexte pour la 3D. Contrairement à la reconstruction simple, le modèle est entraîné à prédire des nuages de points plus denses, ce qui l’aide à appréhender la géométrie des objets, malgré la pauvreté des données d’entrée.
Avec xMOD, l’étiquetage de millions de scènes peut être réalisé sans aucune intervention humaine, avec une précision augmentée par l’utilisation conjointe des modalités caméra et LiDAR.
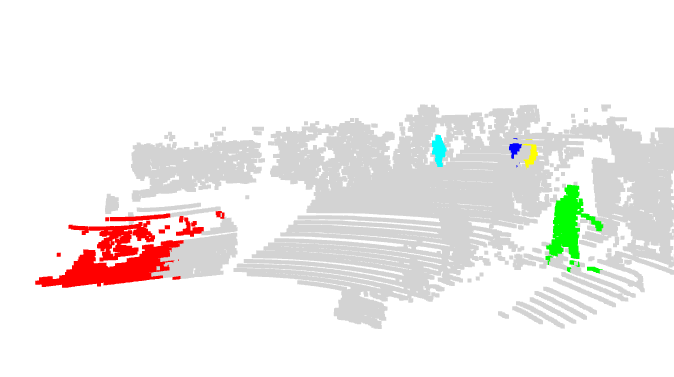
L’approche a été évaluée sur trois jeux de données de référence : synthétiques (TRIP-PD) et réelles (KITTI, Paymo). Le modèle surpasse l’état de l’art de la découverte d’objets 2D avec des gains allant de +8,7 (KITTI) à +15 points (Waymo) de score F1. La stratégie de fusion tardive (combinant les prédictions 2D et 3D lors de l’inférence) améliore encore la fiabilité, notamment pour les objets situés à moyenne distance (10-30 mètres).
Ces avancées en découverte d’objets ouvrent la voie à une conception plus rapide et plus fiable de modèles de perception 3D indispensables aux systèmes de conduite automatisée.
 |
 |
 |
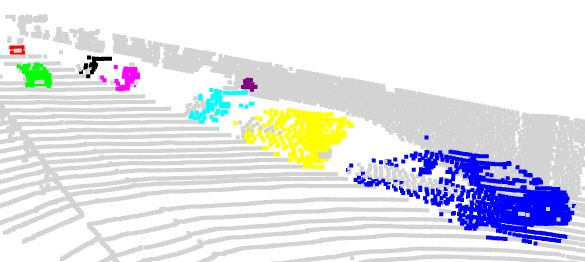 |
| Figure 2 : Visualisation 3D des prédictions produites par xMOD (2D+3D) | |
gain maximal de score F1@50 obtenu par l’approche xMOD par rapport à l’état de l’art de la découverte d’objets 2D.
Embarquer les traitements IA dans les systèmes et appareils intelligents.