

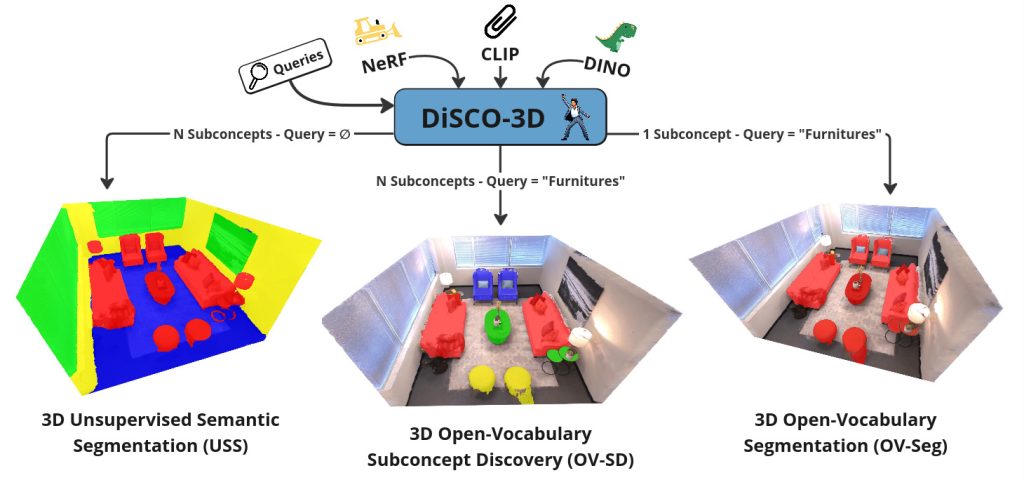
Les méthodes de segmentation sémantique 3D actuelles proposent soit d’identifier les objets correspondant à un unique concept sémantique recherché par l’utilisateur (segmentation en vocabulaire ouvert ou OV-Seg), soit de s’adapter au contenu de la scène en découvrant plusieurs concepts sémantiques (segmentation sémantique non supervisée ou USS).
DiSCO-3D est la première méthode capable d’unifier les deux paradigmes, en abordant le problème plus large de la découverte de sous-concepts sémantiques en vocabulaire ouvert (OV-SD). L’approche proposée vise à découvrir les différents sous-concepts sémantiques de la scène 3D pertinents vis-à-vis d’une requête en langage naturel (figure 1).

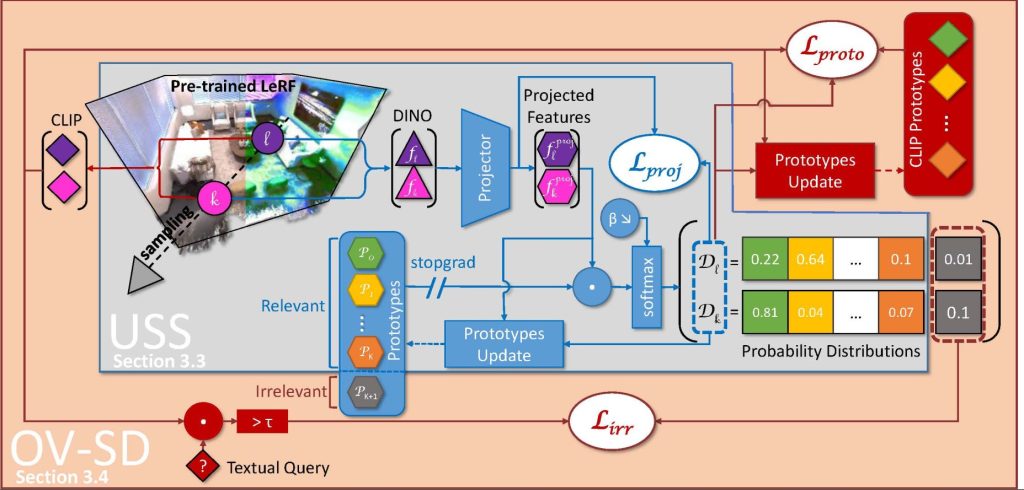
L’architecture de DiSCO-3D (figure 2) comporte deux modules. Le premier réalise la tâche d’OV-Seg pour identifier les zones de la scène ne correspondant pas à la requête de l’utilisateur (fond). Le second module réalise l’USS en forçant l’un des segments à se superposer au fond trouvé. Cette supervision assure ainsi que les autres segments découverts par l’USS correspondent à des sous-concepts sémantiques pertinents pour la requête.
L’efficacité de la méthode est démontrée sur des scènes variées avec différentes requêtes utilisateur (figure 3).

Enfin, les requêtes étant définie en langage naturel, DiSCO-3D peut facilement être intégré comme outil d’une IA agentique, ouvrant les portes de l’analyse de scène 3D à l’aide d’un grand modèle de langage (LLM).
* NeRF : Les Neural Radiance Fields sont une technologie à l’état de l’art qui permet de reconstruire avec un réseau de neurones des scènes 3D à partir d’images 2D.
**LeRF : Les Langage Embedded Radiance Fields étendent les NeRF en associant une information sémantique à chaque point de l’espace.