


En observant les dizaines de milliers de bugs découverts par les plateformes publiques de fuzzing (test aléatoire) comme OSS-Fuzz (Google), il est clair que les capacités de correction de la plupart des équipes de développement ne sont plus à la hauteur. Hormis leur quantité, la clarté des rapports fournis par ces méthodes automatiques en matière d’impact sécuritaire laisse fortement à désirer, ce qui rend pratiquement impossible la priorisation des bugs les plus dangereux en vue de leur correction. La nécessité de développer des techniques automatiques d’évaluation de vulnérabilité et d’exploitabilité se fait donc plus que jamais sentir.
Nos travaux introduisent une formalisation du concept de contrôle de l’attaquant sur une vulnérabilité donnée : à quel degré un attaquant peut-il influencer le comportement d’un certain type de bug au travers des entrées du programme ? Intuitivement, un bug dont les effets peuvent être finement contrôlés par l’attaquant est plus dangereux qu’un bug qui offrirait des possibilités moindres à l’attaquant. Il s’agit donc d’évaluer pour un même bug la quantité de comportements uniques contrôlables par l’attaquant. Mais au-delà de cette simple dimension quantitative, il est également nécessaire de distinguer les différents niveaux de dangerosité de ces comportements et d’intégrer toutes ces informations en un score final unique. Là réside toute la nouveauté et la complexité du problème. Le choix d’employer des méthodes formelles dans ce but garantit la transparence et l’explicabilité des résultats, tout en ouvrant de nouvelles perspectives de recherche dans un domaine jusque-là peu abordé, et où les rares travaux préexistants se fondent toujours in fine soit sur le jugement préalable d’un expert, soit sur des classifications grossières a priori (assigner la même dangerosité à toute une classe de bugs).
Ces travaux ont donné lieu à une publication à Usenix Security 2025, une des conférences scientifiques majeures en sécurité (rang A*) ainsi qu’à un nouveau plugin de la plateforme d’analyse de code binaire BINSEC du CEA-List. Notre approche a été évaluée et validée sur des tâches d’évaluation de vulnérabilités réelles de type corruption de mémoire issues de bases de CVEs (liste de vulnérabilités logicielles) ainsi que d’un benchmark de référence composé de vulnérabilités découvertes par Google OSS-Fuzz. Les programmes ciblés varient de bibliothèques largement utilisées comme libxml2 ou libpng à des systèmes complexes de grande échelle comme openssl ou le bootloader universel u-boot, où notre approche a démontré sa capacité à proposer une classification pertinente de la dangerosité des bugs, au-delà de l’état de l’art actuel.
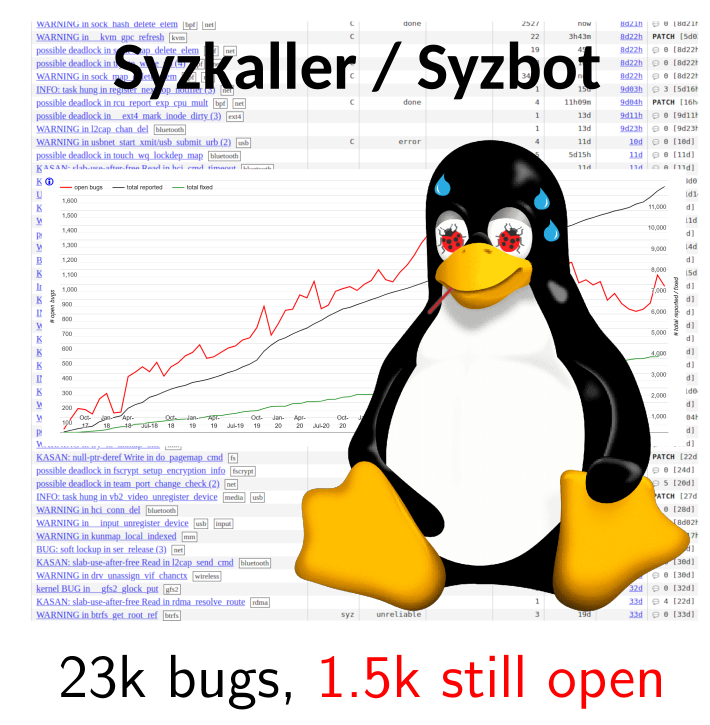
Syzbot (Linux) : 1500+ bugs toujours ouverts
OSS fuzz (Google) : 4000+ bugs toujours ouverts
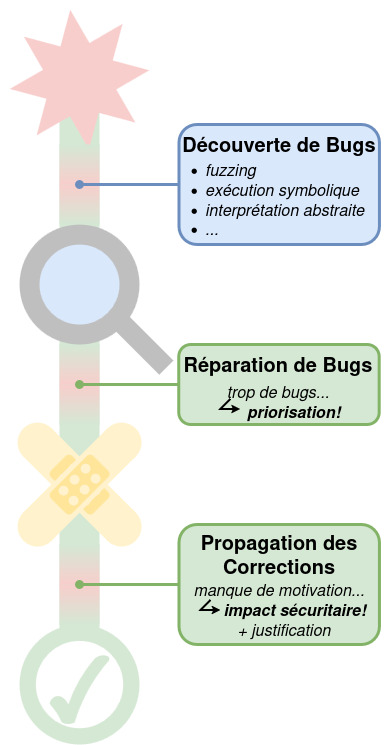
Il est impossible de corriger tous les bugs repérés par les outils de vérification. Par où commencer ?Nous utilisons les méthodes formelles pour les prioriser selon leur dangerosité.
L’évaluation du contrôle d’attaquant sur des bugs ne constitue qu’un premier pas vers l’évaluation automatique de vulnérabilités. De nombreuses problématiques restent en effet à traiter. Comment évaluer d’autres aspects de l’exploitabilité de bugs ? Comment recombiner des résultats d’analyses
disparates en un unique score et en valider la pertinence ? Enfin, comment déployer ces analyses à grande échelle avec un temps de calcul suffisant pour une évaluation à la volée ? Nos travaux marquent un premier pas fondateur, et nous explorons dans le cadre du PEPR Cybersécurité à la fois des extensions conceptuelles et une mise en application réelle.