

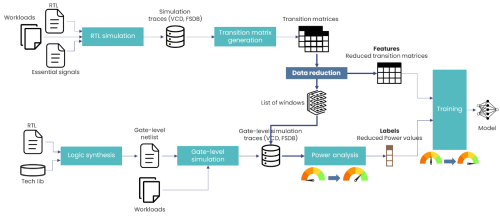
La méthodologie proposée (Figure 1) vise à accélérer la modélisation de la consommation de puissance pour les architectures numériques en combinant apprentissage automatique et réduction drastique du volume de données d’entraînement.
Cependant, ce processus demeure limité par deux goulots d’étranglement majeurs : la lourdeur des simulations au niveau des portes logiques et le coût élevé de la génération des profils de consommation correspondants.
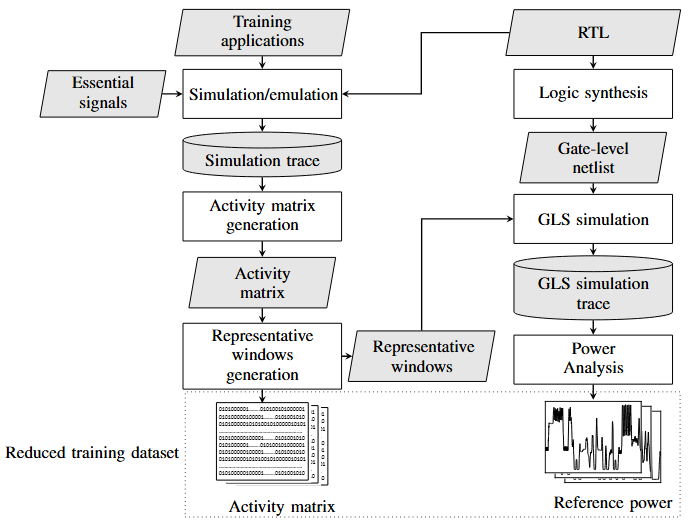
Pour dépasser ces limitations, la méthodologie introduit un mécanisme automatisé de sélection de fenêtres représentatives, fondé sur un clustering « K-means ». Les traces au niveau du transfert de registres sont d’abord segmentées en fenêtres de taille fixe, puis agrégées afin de permettre un clustering robuste sur des séries temporelles complexes. Les fenêtres ainsi identifiées permettent de restreindre l’analyse à un sous-ensemble réduit mais informatif de segments d’exécution, sur lesquels les simulations au niveau des portes logiques et les calculs de puissance sont concentrés. Cela permet de réduire fortement le volume de données à traiter sans compromettre la diversité comportementale nécessaire à l’apprentissage.
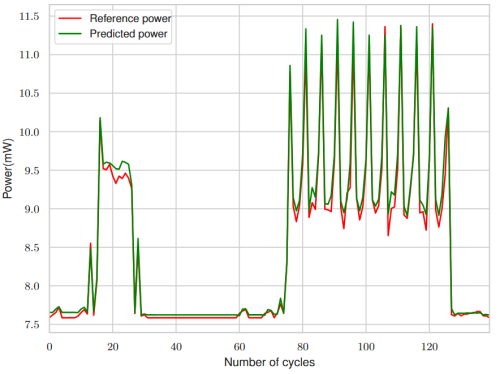
Les résultats expérimentaux, obtenus sur un cœur RISC-V Rocket et un AES masqué, mettent en évidence des gains significatifs : jusqu’à 28× de réduction du temps d’analyse de puissance et jusqu’à 49× de réduction du temps d’entraînement des modèles. Malgré cette compression des données, l’erreur moyenne de prédiction reste autour de 5%. La Figure 2 illustre, à titre d’exemple, une comparaison cycle par cycle d’un segment de la puissance prédite (en vert) et de la puissance de référence (en rouge) pour un AES masqué.
Jusqu’à 28x d’accélération de la phase de génération de données
d’accélération pour l’entraînement des modèles de puissance, tout en conservant une erreur de prédiction autour de 5 %.
En optimisant la sélection des données d’apprentissage, cette approche assistée par l’intelligence artificielle réduit considérablement les besoins en simulation tout en préservant la précision des modèles de consommation de puissance, ouvrant la voie à une modélisation plus rapide et plus scalable.
« A Methodology for Fast and Efficient ML‑based Power Modeling » C. Andriamisaina, K. Trabelsi, P-G. Le Guay, ICCD 2024. https://doi.org/10.1109/ICCD63220.2024.00109