

LIMA est l’analyseur linguistique multilingue développé par le CEA-List. Il s’utilise pour des applications de veille, de GED, de production et de synthèse de rapports ainsi que pour le contrôle de contenus (sur les réseaux sociaux, par exemple). Il est disponible en 60 langues et figure parmi les meilleurs outils du monde pour traiter le français, l’arabe et l’anglais.
LIMA est un outil d’analyse linguistique multilingue. Sa fonction est d’effectuer l’analyse morphologique, syntaxique, sémantique et lexical de contenus textuels. On l’utilise pour des applications requérant de classer des textes, d’extraire automatiquement des parties de documents, de produire des résumés de documents ou, encore, d’analyser des flux de contenus (posts de réseaux sociaux, par exemple). Dans sa version la plus récente (DeepLIMA ou LIMA v3.0), l’outil maîtrise plus de 60 langues avec des performances à l’état de l’art.
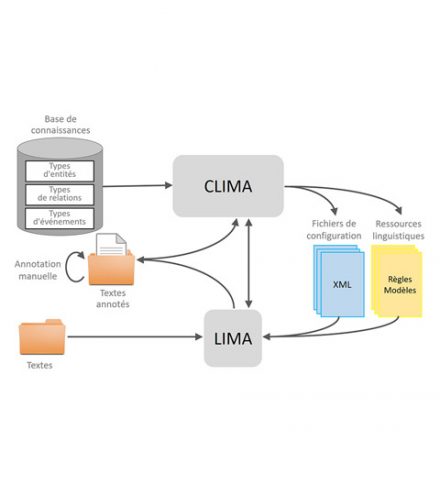
Le moteur est accompagné d’un configurateur, appelé CLIMA, qui permet d’adapter LIMA à un nouveau domaine. CLIMA assiste l’utilisateur dans la définition des structures de connaissances et la fourniture d’exemples utiles à l’adaptation.
LIMA est un logiciel libre, disponible sous la licence MIT. Le CEA-List est à votre disposition pour vous aider à développer des fonctionnalités ou des ressources spécifiques ou si vous avez besoin d’une licence commerciale pour une raison quelconque.

Ses forces principales :
ANT’box est une solution de GED, dont le moteur de recherche sémantique s’appuie sur la technologie LIMA.


Divora est un outil développé par le CEA-List dont la fonction est d’automatiser l’édition de rapports dictés oralement. L’objectif est de permettre à l’utilisateur de produire son rapport, directement sur le terrain, à l’aide d’un terminal nomade muni d’une interface vocale.
Un premier module de reconnaissance de la parole traduit le contenu oral en texte. Un second module, issu de l’analyseur linguistique multilingue LIMA, analyse le texte pour y identifier les termes signifiants ainsi que leurs relations sémantiques, pour la rédaction automatique du rapport.
Divora a été développé dans le cadre d’un projet FactoryLab, pour un domaine applicatif ciblé, l’inspection et le suivi de chantiers.
Pour en savoir plus, lire l’actualité Divora automatise la rédaction de rapports professionnels
A Neural Approach For Inducing Multilingual Resources And Natural Language Processing Tools For Low-Resource Languages, O. Zennaki, N. Semmar, and L. Besacier. Natural Language Engineering, vol. 25, no. 1, p. 43-67, 2019.
Using pseudo-senses for improving the extraction of synonyms from word embeddings, O. Ferret. 56th Annual Meeting of the Association for Computational Linguistics (ACL 2018), short paper session. Melbourne, Australia: Association for Computational Linguistics, 2018, pp. 351-357.
Exploiting a More Global Context for Event Detection Through Bootstrapping, D. Kodelja, R. Besançon, and O. Ferret. 41st European Conference on Information Retrieval (ECIR 2019): Advances in Information Retrieval, short article session. Cologne, Germany: Springer International Publishing, 2019, pp. 763-770.
Joint Learning of Pre-Trained and Random Units for Domain Adaptation in Part-of-Speech Tagging, S. Meftah, Y. Tamaazousti, N. Semmar, H. Essafi, and F. Sadat. 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL HLT 2019), short paper session. Minneapolis, Minnesota: Association for Computational Linguistics, Jun. 2019, pp. 4107-4112.
Multimodal Entity Linking for Tweets, O. Adjali, R. Besançon, O. Ferret, H. L. Borgne, and B. Grau. 42st European Conference on Information Retrieval (ECIR 2020): Advances in Information Retrieval, Lisbon, Portugal, 2020.
