L’IA et le monde de l’embarqué ne font pas toujours bon ménage. La première réclame une quantité exubérante de ressources informatiques et énergétiques pour faire tourner ses milliards de paramètres quand l’autre impose, au contraire, de fortes contraintes de dimensionnement et de consommation.
La solution consiste à réduire la taille des réseaux de neurones artificiels constituant les modèles d’IA. Les chercheurs du CEA-List ont développé une nouvelle méthode de compression capable de réduire la taille de réseaux convolutionnels jusqu’à 60 % et d’accélérer leur inférence de 30 %. Appliquée avec succès aux modèles d’analyse d’images, elle ouvre de nouvelles voies à l’intégration d’algorithmes de perception dans les systèmes embarqués, pour la conduite autonome par exemple, où la capacité de l’IA à traiter très rapidement les images reçues s’avère cruciale.
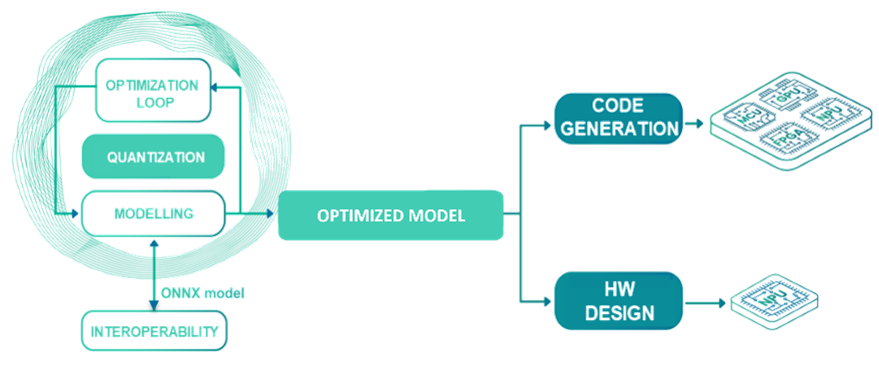
La technologie est intégrée à la plateforme open source pour l’IA embarquée Eclipse Aidge issue du projet DeepGreen. Elle est mise à disposition des industriels pour optimiser le dimensionnement de leur réseau de neurones en fonction des contraintes physiques et informatiques du matériel cible.

Concrètement, la solution intégrée à la plateforme Eclipse Aidge analyse le réseau qu’on lui soumet. Elle définit les paramètres de compression optimaux en fonction des critères spécifiés par l’utilisateur (dimensionnement du matériel cible et ressources disponibles, caractéristiques du cas d’usage, etc.), puis génère automatiquement le réseau compressé avant de l’exporter vers le matériel auquel il est destiné.
La solution fait principalement appel à la méthode de factorisation de bas rang. Cette technique novatrice présente l’avantage de préserver la précision des résultats (la dégradation est de l’ordre de 1 %). Si le principe peut s’illustrer avec des matrices, la véritable avancée réside dans sa généralisation aux tenseurs (matrices de dimensions supérieures à deux). La méthode consiste à décomposer la matrice représentant les nœuds du réseau en un produit de matrices plus petites. Comportant moins de nœuds, ces dernières nécessitent moins de ressources en calcul et en mémoire, ce qui réduit la consommation d’énergie et accélère l’exécution des opérations.
Ce module de compression basé sur la décomposition tensorielle est combiné à une seconde méthode de compression déjà existante – la quantification, qui réduit la précision des paramètres des nœuds – afin d’exploiter sa complémentarité avec la factorisation.
Les travaux de recherche se poursuivent sur une cohabitation plus sophistiquée de ces deux approches pour optimiser davantage la compression.
Piloté par le CEA, DeepGreen est un collectif d’une vingtaine de partenaires français de la recherche et de l’industrie, désireux de mutualiser leurs efforts pour construire des solutions souveraines d’IA embarquées et de confiance.
Le consortium a mis en place la plateforme open source Eclipse Aidge, qui rassemble un outillage complet pour élaborer des systèmes d’IA destinés à être embarqués, ainsi qu’un ensemble de démonstrateurs qui mettent en avant des technologies souveraines. Aidge intègre en son cœur l’environnement N2D2 du CEA-List.
DeepGreen est un projet du programme France 2030.

La solution de compression intégrée à Eclipse Aidge est une concrétisation notable des recherches du CEA-List sur le sujet de la compression de réseaux de neurones.
D’autres axes sont explorés, parmi lesquels celui de la préservation des propriétés initiales des réseaux, notamment leur robustesse face aux cyberattaques. Ces recherches sont menées dans le cadre du projet HOLIGRAIL (HOListic Approaches to GReener model Architectures for Inference and Learning) du PEPR IA (Programme et équipements prioritaires de recherche IA).
Pour en savoir plus : lire l’article Lancement du PEPR Intelligence artificielle, un grand programme de recherche en soutien de l’innovation et des usages émergents de l’IA
Les équipes du CEA-List travaillent également à la généralisation des méthodes de factorisation de bas rang pour les appliquer à toutes sortes de tenseurs. L’un des objectifs est d’utiliser ces méthodes pour compresser les réseaux de neurones utilisés par les grands modèles de langage (LLM, Large Language Model), réputés pour le gigantisme de leur dimension et de leur consommation énergétique.

Le module de compression développé par nos équipes permet de réduire notablement les dimensions d’un réseau de neurones convolutionnel, tout en préservant ses caractéristiques de performances et de robustesse.
Il devient possible de réduire un réseau de neurones pour l’embarquer dans un environnement contraint, mais aussi, à l’inverse, de définir le taux de compression possible étant donné une cible matérielle pour maximiser le dimensionnement initial du réseau.