

Streamer propose un environnement complet permettant aux data scientists d’expérimenter leurs algorithmes d’apprentissage sur des données en flux. Ouvert, multi-OS et disponible en open source, Streamer automatise toute la chaîne de traitement des flux de données. Il offre une grande latitude au data scientist pour configurer ses flux et lui permettre ainsi de mener ses études dans les conditions les plus réalistes possibles, tout en minimisant drastiquement le temps requis pour mettre en œuvre son environnement de travail.
Streamer est un environnement de traitement automatique de flux de données permettant l’expérimentation, de manière réaliste, d’algorithmes de machine learning travaillant en continu. Il effectue toutes les opérations de la chaîne de traitement, de l’ingestion des données jusqu’à la visualisation des résultats des opérations.
Streamer épargne ainsi au data scientist le développement – complexe et chronophage – de la chaîne de traitement. Ce dernier peut se concentrer sur la mise au point de ses algorithmes. L’environnement met à sa disposition des outils de préparation et de post-traitement des données, des algorithmes avancés d’apprentissage en flux et des outils d’évaluation des fonctions. Il présente aussi des API pour l’intégration d’outils et algorithmes tiers écrits dans de nombreux langages de programmation (Python, R, Java, etc.). Il fournit, par ailleurs, une interface graphique facilitant le suivi des processus d’apprentissage et d’analyse des flux de données.
Le code de Streamer est disponible en open source (licence GNU GPL 3) pour permettre aux data scientists de le modifier et d’y ajouter les fonctions qu’ils souhaitent. L’environnement se présente, cependant, également comme une application directement exécutable et utilisable dans un contexte opérationnel.
Streamer a été développé conjointement par des équipes du List et du laboratoire DAVID (Données et algorithmes pour une ville intelligente et durable, Université Paris-Saclay, UVSQ) dans le cadre du projet StreamOps, financé par l’Institut DATAIA.

Ses forces principales :
Nous utilisons Streamer, que nous avons codéveloppé avec le CEA-List, dans le cadre du projet ANR Polluscope. Ce projet vise à développer des algorithmes pour caractériser l’exposition individuelle à la pollution de l’air, en exploitant les flux de mesures collectées par des micro-capteurs
Streamer permet de développer des applications d’IA capables d’apprentissage en continu :
Les experts en cybersécurité comptent de plus en plus sur les algorithmes d’apprentissage automatique pour les assister dans l’évaluation et la contextualisation des menaces et des alertes. Dans le cadre d’un programme de recherche interne, le CEA-List a montré l’apport de Streamer pour mettre au point et encadrer l’exploitation de ces algorithmes :
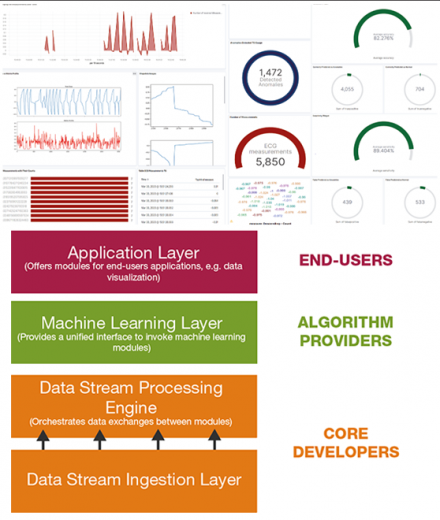
STREAMER: a Powerful and Open-Source Framework for Continuous Learning in Data Streams, Garcia-Rodriguez, Sandra, Mohammad Alshaer, and Cedric Gouy-Pailler. Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 2020.
Detecting Anomalies from Streaming Time Series Using Matrix Profile and Shapelets Learning, Mohammad Alshaer, Sandra Garcia-Rodriguez and Cedric Gouy-Pailler. Proceedings of the 32th ACM International Conference on Tools with Artificial Intelligence. 2020.
Pour en savoir plus, accéder à Streamer


