


Pour leur conception, les modèles statistiques utilisés pour concevoir les systèmes d’intelligence artificielle doivent être entraînés sur de grandes quantités de données – parfois personnelles et/ou sensibles – préalablement étiquetées Leur confidentialité est donc au cœur des enjeux de l’IA
L’apprentissage fédéré, un protocole de mutualisation des efforts
Lorsque plusieurs acteurs (individus, institutions) collaborent pour entraîner un modèle commun, sans partage de données, l’apprentissage fédéré permet de distribuer la tâche d’apprentissage entre eux puis d’agréger les mises à jour du seul modèle sur un serveur central. Ce procédé évite ainsi à chaque acteur de divulguer ses données.
Cependant, l’apprentissage fédéré implique nécessairement d’envoyer le modèle aux clients, ce qui pose un problème de sécurité. Des attaques dites « par inversion de modèle » ont été récemment découvertes : un client participant à l’entraînement ou un agent malveillant ayant accès au serveur pourrait tenter d’inverser le traitement effectué et accéder ainsi à des données personnelles.
La confidentialité différentielle, un paradigme de protection
Pour protéger ces données, le paradigme de la confidentialité différentielle consiste à s’assurer que l’on ne puisse pas déterminer si une certaine donnée (personnelle par exemple) a été utilisée ou non pour l’entraînement du modèle.
Une méthode usuelle pour assurer la confidentialité différentielle consiste à additionner un bruit aléatoire au résultat du traitement, que ce soit par le serveur avant l’envoi du modèle ou par les clients. Cependant, ce bruitage diminue la performance du modèle, c’est-à-dire la précision des prédictions fournies. Nous avons donc concentré nos recherches sur l’amélioration du compromis entre la confidentialité et la performance des modèles d’IA.
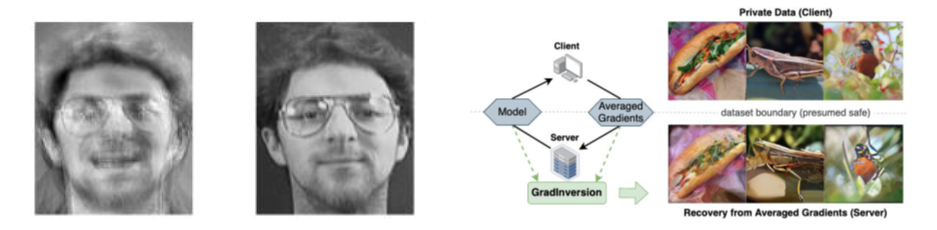
Images reconstruites à l’aide d’une attaque par inversion :
Image de gauche : exemple d’attaque sur un modèle d’intelligence artificielle pour parvenir, à partir du modèle uniquement, à reconstruire les données d’entraînement. La figure présente une image reconstruite à gauche à partir du modèle, et sa comparaison avec un exemplaire de la base de données d’entraînement, non connu par l’attaquant.
Image de droite : second type d’attaque ciblant cette fois les gradients échangés à chaque itération d’apprentissage. A partir de ces gradients, l’attaquant peut reconstruire des données extrêmement fidèles aux données originales, sans les connaître au préalable.
Pour améliorer ce compromis, le CEA-List a développé le protocole « SPEED » d’apprentissage fédéré, qui a fait l’objet d’une publication scientifique dans Machine Learning2. Le protocole considère qu’en plus des différents clients, le serveur central n’est pas non plus un agent de confiance. Il se fonde sur un principe de « vote » : des clients entraînent une version miniature du modèle en question, avec leurs données personnelles. Ensuite, le serveur leur présente des données publiques brutes et vote pour les étiqueter avec leur modèle miniature.
Pour traiter les votes de manière anonyme, SPEED intègre la technologie du chiffrement homomorphe : les clients peuvent chiffrer leurs votes, et le serveur les agréger sans les déchiffrer (le serveur n’a pas accès aux votes individuels en clair). Nous avons démontré sur des modèles de test l’efficacité de SPEED par rapport aux travaux existant dans la littérature scientifique. Contrairement au protocole PATE par exemple3, SPEED protège les données du serveur, et ce, sans compromettre la précision du modèle.
Le chiffrement homomorphe se base sur des algorithmes dits « approchés » car ils ne sont pas exacts. Ils nécessitent en effet une quantification, consistant à passer de données continues à discrètes. Cette quantification introduit ainsi un bruit « naturel » aux données, comparable à une erreur d’arrondi. De récents travaux du CEA-List fournissent des garanties théoriques de leur effet de bruitage.
Nous avons ainsi développé un nouvel opérateur « argmax » nommé SHIELD, utilisable par exemple pour agréger les votes dans SPEED. En étant volontairement moins précis, cet opérateur réduit le coût de calcul de l’algorithme tout en garantissant la confidentialité différentielle4.
Les méthodes développées ont un fort potentiel d’application dans les domaines de la santé et de la biométrie, qui traitent des données particulièrement sensibles liées aux individus.
Elles ont également déjà trouvé des applications dans le domaine de la sécurité, en renforçant la confidentialité des systèmes de reconnaissance faciale, qui utilisent de nombreuses données d’entraînement, souvent partagées par des institutions.
Nous cherchons aujourd'hui à étendre notre champ applicatif dans le cadre de projets européens, notamment en cybersécurité. La combinaison des différentes techniques que nous avons développées permet par exemple de protéger les partages de signatures de données en cybersécurité. Celles-ci peuvent par exemple provenir d’agences gouvernementales, qui doivent faire face à différentes menaces. Nous échangeons par ailleurs avec de plus en plus d’industriels intéressés par ces techniques, soucieux de garantir au mieux leurs données sensibles sans s’interdire d’en tirer de la valeur grâce à des techniques d’IA.
1. Yin, H., Malya, A. Vahdat et al (2021), See through Gradients: Image Batch Recovery via GradInversion. arxiv:2104.07586
2. Grivet Sébert, A., Pinot, R., Zuber, M. et al (2021). SPEED: secure, PrivatE, and efficient deep learning. Machine Learning 110, 675–694.
3. Papernot, N., Abadi, M., Erlingsson, U., Goodfellow, I., & Talwar, K. (2017). Semi-supervised knowl-edge transfer for deep learning from private training data. 5th international conference on learning representations.
4. Grivet Sébert, A., Zuber, M., Stan, O. et al (2023). When approximate design for fast homomorphic computation provides differential privacy guarantees. arxiv:2304.02959


