


Le challenge EvalLLM 2024 visait à évaluer les approches reposant sur des modèles de langue neuronaux dédiés à la reconnaissance d’entités nommées, pierre angulaire de l’extraction d’information. Cette tâche s’effectuait dans un contexte few-shot, c’est-à-dire avec peu de données annotées, et en français, langue moins dotée que l’anglais. Dans les cas réels d’application de l’extraction d’information, les données annotées permettant d’adapter les modèles ne sont que très rarement disponibles en quantité suffisante pour être exploitées par des modèles d’apprentissage supervisé traditionnels. C’est pourquoi le challenge EvalLLM s’est concentré sur un nombre limité de documents d’entraînement : 4 bulletins d’information et un article de blog (Figure 1).
Dans une telle configuration « fewshot », la question majeure est la suivante : est-il préférable d’exploiter un grand modèle de langue génératif ou un modèle de langue bien plus petit, de type encodeur ? Pour répondre à cette question, le CEA s’est appuyé sur deux modèles : GoLLIE (Sainz et al., 2024) et GLiNER (Zaratiana et al., 2024). GoLLIE, fondé sur le modèle génératif Code-LLaMA 13B, transforme la tâche de reconnaissance d’entités nommées en tâche de génération de code par le biais de prompts similaires à la figure 2 :

GLiNER, fondé sur des modèles encodeurs de type BERT, apprend quant à lui à mettre en correspondance des représentations de mentions d’entités candidates et les représentations des types d’entités possibles, utilisés comme prompt (cf. Figure 3).
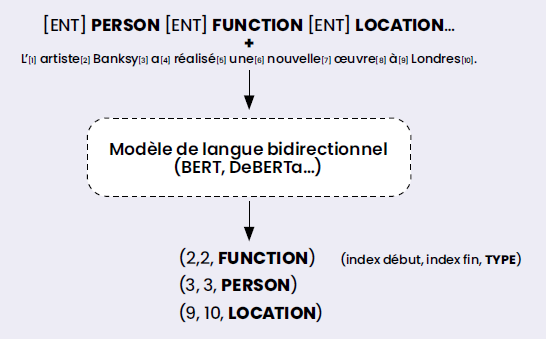
Ces deux modèles ont la particularité commune d’avoir été pré-entraînés à grande échelle en utilisant des jeux de données en anglais non liés au domaine cible de l’évaluation (des données annotées manuellement dans le cas de GoLLIE et produites automatiquement à partir de ChatGPT pour GLiNER).
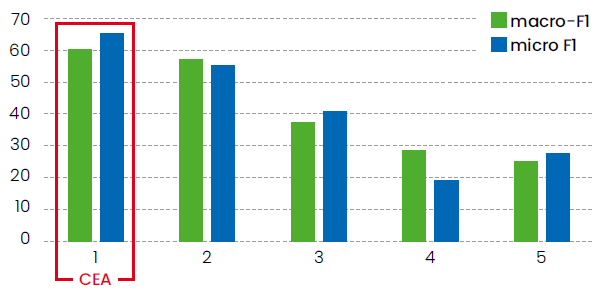
L’application de ces deux modèles aux données de test de l’évaluation a montré une nette supériorité du modèle GLiNER sur le modèle GoLLIE, avec un gain de 62 % en macro-F1 et de 118,6 % en micro-F1.
Il dépasse les performances du modèle GPT-4o, très nettement plus gros, utilisé par les participants arrivés en 2e position (Figure 4).
Au-delà de l’évaluation EvalLLM 2024, les perspectives sont parallèlement de transposer les résultats obtenus sur des données du domaine de la sécurité dans le cadre de projets européens en cours et d’améliorer la dimension few-shot du modèle GLiNER en lien avec le projet Sharp du PEPR IA sur la thématique de la frugalité.
Les modèles de génération d’image conditionnés par le texte, tels que Stable Diffusion, obtiennent des résultats visuellement impressionnants. Néanmoins, leur capacité à suivre précisément des consignes textuelles n’est pas toujours bien établie. C’est pourquoi nous avons développé la métrique TIAM, alliant la génération contrôlée de consignes textuelles et des outils d’analyse d’images pour établir dans quelle mesure un modèle respecte le nombre d’objets ou la couleur spécifiés. Les études menées sur les six modèles d’IA existants les plus utilisés montrent que leur capacité à respecter une consigne spécifiant plus d’un objet est encore limitée, et davantage lorsqu’une couleur est précisée. TIAM peut donc aider à mieux comprendre l’influence des paramètres d’entraînement des IA sur la compréhension et le respect des consignes, ouvrant ainsi une nouvelle voie de recherche sur le noise mining, c’est-à-dire la quête des “bons” bruits qui augmentent la qualité des résultats d’une IA.
Le CEA applique ses travaux sur les modèles few-shot de reconnaissance d’entités nommées dans le cadre des projets européens sur la sécurité VANGUARD, ARIEN et STARLIGHT. Ces modèles doivent permettre d’analyser des contenus textuels -en particulier issus des réseaux sociaux- pour lutter contre les trafics de nature criminelle.
« CEA-List@EvalLLM2024 : prompter un très grand modèle de langue ou affiner un plus petit ? »
Robin Armingaud, Arthur Peuvot, Romaric Besançon, Olivier Ferret, Sondes Souihi et Julien Tourille.
EvalLLM2024 : Atelier sur l’évaluation des modèles génératifs (LLM) et challenge d’extraction d’information few-shot, Toulouse, France.

