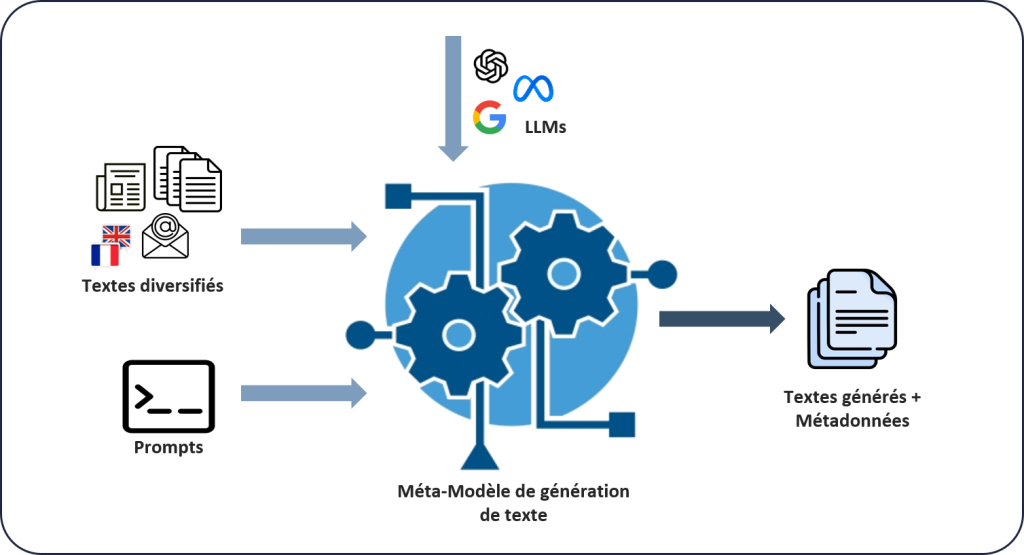
Le principe est de faire collaborer un système de génération de textes à partir de données cible avec un système de détection de textes générés par intelligence artificielle. Le système de génération de textes (figure 1) contient un méta-modèle de génération sur lequel des modèles à l’état de l’art peuvent se greffer. Il prend en entrée des textes sources cibles en français et anglais, et génère des textes similaires (LLMs utilisés : Llama2 7b Chat, Flan-T5 XXL, Bloomz 7b1 Mt, Falcon-7B Instruct, GPT4All 13B snoozy et OpenAI GPT3.5).
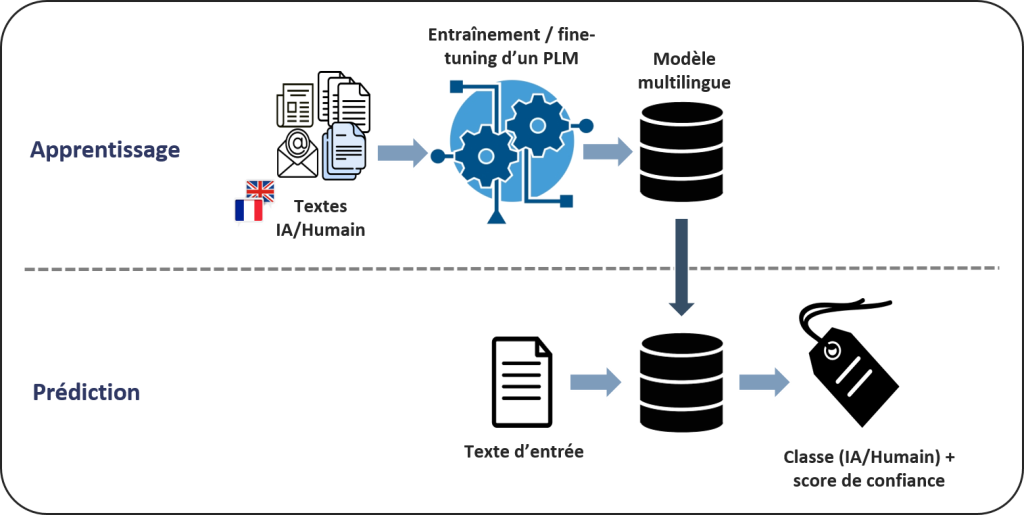
Le système de détection (figure 2) détecte les textes générés par intelligence artificielle avec une approche « black-box » qui fonctionne sur des modèles open-source et propriétaires. Ce système se base sur un modèle multilingue « fine-tuné » qui classe le texte d’entrée et y associe un score de confiance. Pour cette tâche, les modèles Transformer bidirectionnels semblent plus efficaces que les modèles autorégressifs. En termes de score F1, mDeBERTa V3 devance presque toujours mBERT et XLM-RoBERTa.
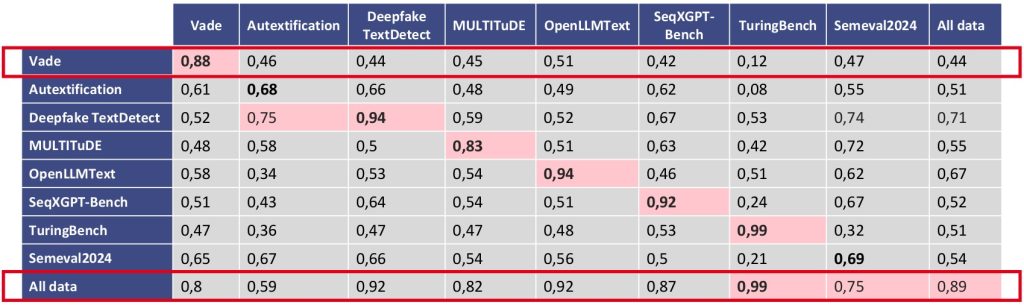
L’objectif étant de généraliser le système à de nombreux autres datasets, des expérimentations ont été menées avec mDeBERTa V3. Les scores F1 sont présentés sur la figure 3. Ces résultats démontrent l’efficacité de l’approche « blackbox » et soulignent l’importance de diversifier les jeux de données d’entraînement pour renforcer davantage la robustesse de la détection.